
Earlier I had written a post about using OpenAI APIs to create a stock sentiment analysis by feeding news to GPT models. In this post, I am going to introduce the concepts of Word Embeddings or Embeddings in general. I am going to write a product recommendation system using OpenAI embeddings API that consumes product-related datasets from Kaggle. If you are in hurry or not interested in technical details, check the demo video below:
Before I start developing the system itself, allow me to discuss a few words about embeddings and their need.
What are embeddings
According to Wikipedia:
In natural language processing (NLP), a word embedding is a representation of a word. The embedding is used in text analysis. Typically, the representation is a real-valued vector that encodes the meaning of the word in such a way that the words that are closer in the vector space are expected to be similar in meaning.[1] Word embeddings can be obtained using language modeling and feature learning techniques, where words or phrases from the vocabulary are mapped to vectors of real numbers.
In essence, it is a method for representing complicated data in a lower-dimensional space, such as words, sentences, photos, and videos. Consider embeddings as a means to convert words or sentences into numeric representations. Every word or phrase has a distinct set of numbers assigned to it, and these numbers convey the context and meaning of the words. Computers can so comprehend and manipulate the underlying meaning of the words rather than merely text by using these numbers. It is similar to assigning a unique code to every word to improve the computer’s linguistic comprehension.
Explain Embeddings like I am 5
Imagine you have a box filled with tons of toys, all jumbled together. It’s fun to play with them, but sometimes it’s hard to find the one you want because everything is mixed up.
Embeddings are like a special sorting game for your toys! They take each toy and give it a secret sticker with just a few colored dots on it. Each dot stands for something special about the toy, like its color, size, or what it makes a sound.
Now, instead of looking at all the toys at once, you can just look at their stickers. If two stickers have the same colors in the same places, that means the toys are probably similar! This makes it much easier to find the toy you want, even if it’s hiding in a big pile.
That’s what embeddings do with grown-up things like words, pictures, and even music! They turn them into small codes that capture what’s important about them, so computers can understand them better and do cool things like:
- Show you pictures of dogs when you search for “furry friend”
- Recommend books you might like based on other stories you enjoyed.
So, while embeddings might sound complicated, they’re really just a clever way to organize and understand things by using secret codes!
Why Are Embeddings Called ‘Embeddings’?
The term “embedding” is derived from the concept of embedding something into a space with fewer dimensions. In the context of word embeddings, words are represented as vectors (mathematical entities with both magnitude and direction) in a continuous vector space. This process allows words to be positioned in a way that captures their semantic relationships and contextual meanings. Here are some potential interpretations:
- Embedding like embedding a gem: Imagine a precious gem set within a ring. The gem (complex data) is embedded within the ring (simpler space), preserving its essence while being integrated into a new structure.
- Embedding is like embedding oneself in a culture: Immersing yourself in a different culture involves understanding its nuances and relationships within its structure. Similarly, embeddings capture the “meaning” of data by understanding its connections within a lower-dimensional space.
- Embedding like encoding information: Embedding involves encoding complex data using a more concise representation, akin to how information is “embedded” within symbols or codes. It’s not a direct translation, but rather a compressed version retaining key aspects.
How are word embeddings made?
Large text datasets are used to train neural network models, which create word embeddings. Word2Vec and GloVe are two popular techniques for generating word embeddings, while there are other methods as well. Several algorithms contribute to the exciting world of word embeddings, each with its own strengths and weaknesses. Here are some of the most prominent:
1. Word2Vec:
- This popular option features two variants: Continuous Bag-of-Words (CBOW) and Skip-gram.
- CBOW predicts a target word based on its surrounding context words, helping capture semantic relationships.
- Skip-gram predicts surrounding context words based on a single input word, focusing on capturing syntactic nuances.
- Both rely on neural networks and offer efficient representation of frequent words.
2. GloVe (Global Vectors for Word Representation):
- This algorithm leverages statistical information from co-occurrence matrices, analyzing how often words appear together in a corpus.
- It aims to capture both semantic and syntactic information, offering good performance for rare words.
- While not utilizing neural networks, it allows for faster training and larger vocabulary handling.
3. FastText:
- This extension of Word2Vec incorporates subword information, breaking words into smaller meaningful units (e.g., morphemes).
- This allows for handling out-of-vocabulary words by combining subword embeddings, making it adaptable to diverse vocabularies.
4. ELMo (Embeddings from Language Models):
- This contextual word embedding approach analyzes words based on their entire sentence context, utilizing a bidirectional language model.
- This captures dynamic word meanings depending on the sentence, suitable for tasks like sentiment analysis and text summarization.
5. BERT (Bidirectional Encoder Representations from Transformers):
- This powerful transformer-based model considers surrounding words and their positions, capturing richer contextual information.
Use Cases of Embeddings:
-
Text:
- Recommendation systems: Suggest similar products, articles, or music based on user preferences.
- Chatbots and virtual assistants: Understand user queries and respond in a relevant and human-like way.
- Sentiment analysis: Classify the sentiment of text (positive, negative, neutral) for targeted marketing or social media analysis.
- Machine translation: Translate text from one language to another while preserving meaning and context.
- Text summarization: Generate concise summaries of large bodies of text.
-
Images:
- Image search and retrieval: Find similar images based on their content and visual features.
- Image classification: Categorize images into different classes (e.g., animals, objects, landscapes).
- Image captioning: Automatically generate captions for images that describe their content.
- Anomaly detection: Identify unusual or suspicious images in large datasets.
-
Other Data Types:
- Recommendation systems for products, movies, etc.: Similar to text recommendations, using product features or user preferences.
- Fraud detection: Identify fraudulent transactions or activities based on user behavior patterns.
- Drug discovery: Find new drugs by analyzing molecular structures and their similarities to known drugs.
- Social network analysis: Understand relationships and communities within networks of users.
-
Additionally:
- Embeddings can be used for dimensionality reduction, making complex data easier to process and analyze.
- They can be combined with other machine learning techniques to improve the performance of various tasks.
- As research advances, new and innovative applications for embeddings are constantly emerging.
Alright..enough theoretical information has been provided, let’s start writing some code, shall we?
Development
As mentioned, I am going to develop a product recommendation system using Walmart data from Kaggle. Though it contains items from multiple categories I specifically extracted food-related items for further development. Before I start coding, let me share the entire flow of the system.

Look simple, right? It is! I have divided the code into two parts: a Jupyter notebook for explaining the purpose and a Python Flask application to display similar products. I will be sharing code later in a repo so hence discussing the main parts of the program. So let’s discuss one by one. We will be loading API_KEY which is defined in .env file.
from dotenv import dotenv_values
config = dotenv_values(".env")
OPENAI_EMBEDDINGS_KEY = config['API_KEY']
Loading Products CSV and Filtering
csv_file = 'walmart.csv'
text_columns = ['Product Url', 'Product Name', 'Description','List Price', 'Brand']
df = pd.read_csv(csv_file)
missing_values = df['Category'].isna().any()
if missing_values:
df['Category'].fillna('', inplace=True)
# Filter the DataFrame to include only records where 'Category' contains 'Foods'
df = df[df['Category'].str.contains('Foods', case=False)]
columns_to_remove = ['Crawl Timestamp', 'Item Number','Gtin','Package Size','Category','Postal Code','Available','Sale Price','Brand']
# Drop the specified columns
df.drop(columns=columns_to_remove, inplace=True)
df['Combined_CSV'] = df.apply(combine_to_csv, axis=1)
small_df = df.tail(500)
Nothing fancy. After loading the CSV file in a dataframe variable,df, I then filtered records from foods related categories and after removing unwanted columns I stored them in small_df variable.
Combining Columns For Embedding
# Function to combine specified columns into a CSV-formatted string
def combine_to_csv(row):
return ','.join(['"{}"'.format(str(value).strip()) if col != 'List Price' else str(value).strip() for col, value in row[['Uniq Id','Product Name', 'Description', 'List Price']].items()])
df['Combined_CSV'] = df.apply(combine_to_csv, axis=1)
small_df = df.tail(500)
The function combine_to_csv just concatenate the relevant columns’ data in CSV format and store them in a new column Combined_CSV. Later, this column will be used to create product embeddings. The small_dfcontains the last 500 records
Generate Batches and Embeddings
Alright, the data is ready, it’s time to create embeddings. OpenAI’s create embeddings API accept either a string or an array as input. Creating multiple embeddings in a go is efficient since it makes fewer requests yet gives individual embeddings. But there’s a caveat, there is a limit to the maximum input which is 8191 for all embedding models.

We are going to use text-embedding-3-small model which is quite cheap and serves the purpose. So, the way to deal with it is to divide records into several batches based on the MAX INPUT limit.
def create_batch_records(df,max_tokens=8191):
"""
This function will iterate the df's COMBINED cloumn.
each record will be passed to "num_tokens_from_string" function
to calculate total tokens by each record
"""
batch = []
batches = []
remaining_token = max_tokens
for index, row in df.iterrows():
text = row['Combined_CSV'].lower().strip()
token_count = num_tokens_from_string(text)
batch.append(text)
remaining_token = remaining_token - token_count
if token_count >=remaining_token:
batches.append(batch)
batch = []
remaining_token = max_tokens
return batches,len(batches)
Once batches are prepared, it’s time to create embeddings.
embedding_found = True
formatted_embeddings = []
all_embeddings = []
merged_embeddings = []
x = 0
# load the cache if it exists, and save a copy to disk
try:
merged_embeddings = pd.read_csv("allembeds.csv")
print("Embedding File Found")
except FileNotFoundError:
print("Embedding File Not Found...")
embedding_found = False
if not embedding_found:
print("Creating Batches and Embeddings")
batches,count = create_batch_records(small_df)
for batch in batches:
records,embeddings = generate_embeddings(batch,client,EMBEDDING_MODEL)
formatted_embeddings = format_embeddings(records,embeddings)
all_embeddings.append(formatted_embeddings)
x+=1
if x > 2: # No specific reason, did not want to consume my OpenAI account
break
for emb in all_embeddings:
for rec in emb:
merged_embeddings.append(rec)
if not embedding_found:
df = pd.DataFrame(merged_embeddings, columns =['UniqueID','Title','Desc','Price','Embedding'])
df['Price'] = pd.to_numeric(df['Price'], errors='coerce').fillna(0.0)
df.to_csv('allembeds.csv', index=False)
I am making sure that allembeds.csv exist, if it’s there, then use the already computed embeddings otherwise make a call to OpenAI servers. Once embeddings are ready, I just iterate all products in batches and store their embeddings into a single-dimensional array. After that stored them in allembeds.csv file.
Creating Embedding For The Input Query
Alright! The embeddings of each product are ready and stored in the CSV file. Now I will be creating the embedding of the input query
query = input("Enter product title")
emb_query = generate_single_embedding(query,client,EMBEDDING_MODEL)
Cosine Similarity Computation
Cosine Similarity is one of the distant formulas used to find the nearest point against a given point. The other formulas are Euclidean Distance and Manhattan Distance.
text_embedding_array = np.array(emb_query) text_embedding_reshaped = text_embedding_array.reshape(1, -1) similarities = compute_similarity(text_embedding_reshaped, extracted_embeddings)
I calculate similarities after converting into a numpy array and then from 1D to a 2D array. Below are two graphs about Cosinme Similarity and Input Query Embedding vs All Embeddings:
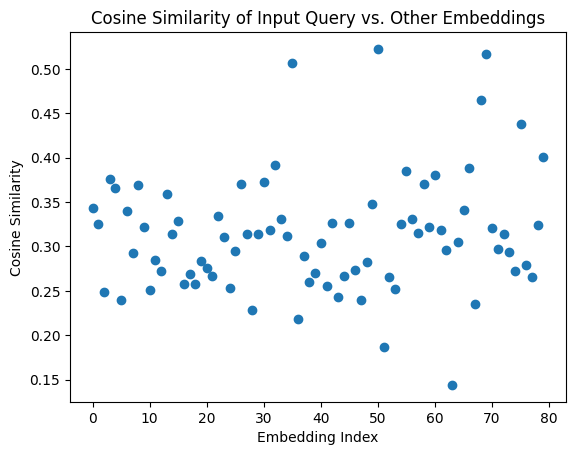
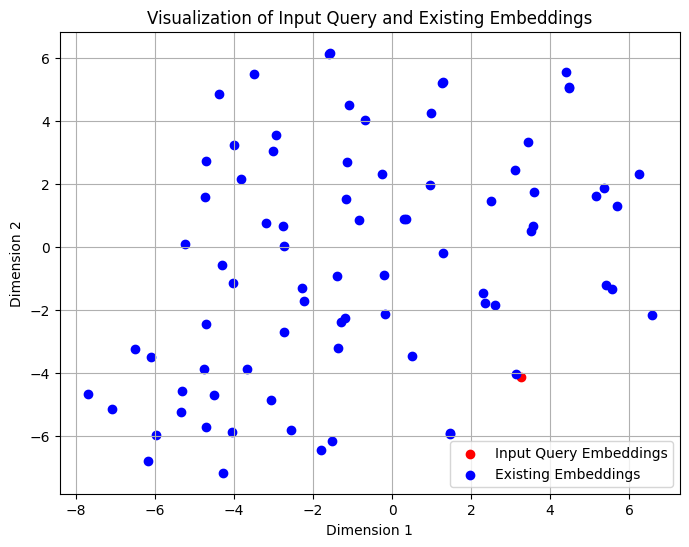
The above charts depict the outcome of the input query, Health Warrior Chia Bar, Acai Berry, 25 G, Pac. The red dot near a blue dot tells that the input text is very similar to this nearby blue one.
Displaying Top 5 Products
top5 = top_5_similar_records(similarities,small_df,query) top5
If I run the above query, it produces the following output:
[('Health Warrior Chia Bar, Acai Berry, 25 G, Pack Of 15',
'21fee4394b9cc53bb6ddbe4235506a5c',
0.7865167078326643),
('Rise Bar Gluten Free Protein Bars, Chocolatey Coconut, 2.1 Oz, 12 Ct',
'076ce5498d181a517bdc2863142402c0',
0.46839342705774173),
('Nutrisystem Chocolate Chip Baked Bars Pack, 5 Count - Ready to Eat Meal Replacement Breakfast Bars to Support Healthy Weight Loss',
'202ab4c56b418153657e2b53b30ef9b3',
0.4606601758761113),
('Pure Organic Pineapple Passion Fruit Bars 0.63 oz 12 ct',
'269fc6604182f3c027e25280fdffb95b',
0.4472399354429031),
('Go Raw 100% Organic Spirulina Super Chips, 3 oz, (Pack of 12)',
'08b116626df671a2ad3fb1b1de9d179c',
0.4471157111214574),
('Natures Way Barley Grass Bulk Powder Dietary Supplement, 9 oz',
'18fc594859d86f440890e87bafa95ef5',
0.43024825369566544)]
The first product is around 79% similar to the input query, as you can see yourself the most relevant output is Health Warrior Chia Bar, Acai Berry, 25 G, Pack Of 15 while the input query contains Health Warrior Chia Bar, Acai Berry, 25 G, Pac. You might argue that the difference is subtle then why cosine similarity is 0.78 (Btw, cosine similarity ranges between 0 and 1), why not near 1 or even 0.9. The reason is these embeddings do not consist of the product title only but also contain the Price, UniqueID, and Description columns which would have varied from the input query to the matched product.
Demo Website
Now it’s time to make the entire thing into a working demo. A simple Flask-based app that shows product listing from the database and then individual products with the listing of similar products.

Do remember that these similar products are not based on a “Full Text” search or anything but Semantic Search.
Conclusion
So in this post, we learned embeddings could be used for recommending relevant products. There have been many posts, in fact, products that let you question PDF files but not much about using embeddings for recommendation purposes. I hope you’d have enjoyed it. Like always, the code is available on GitHub.
Interested in building something similar or other AI/LLM related apps, contact at kadnan @ gmail.com



