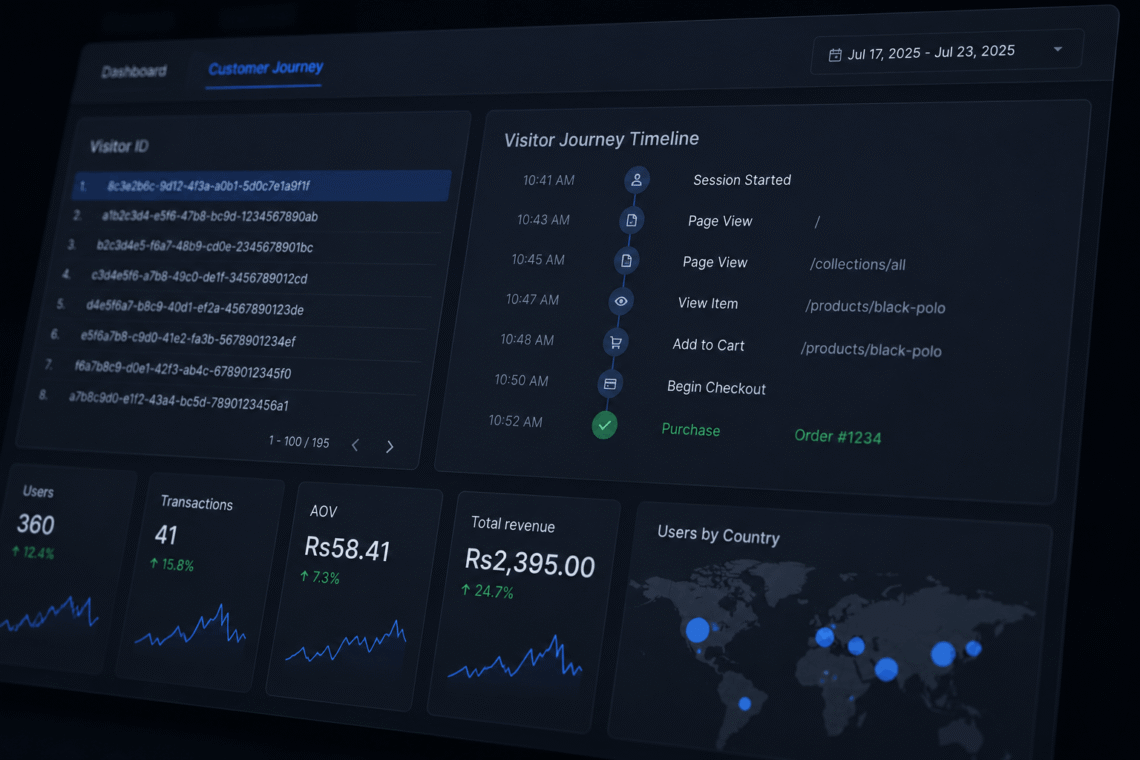
In my previous article, I explained how I implemented browser-side and server-side tracking for a Shopify store using Google Tag Manager, GA4, and Meta CAPI. Once it was done, the next step was making that data useful. This article covers the dashboards I built in Looker Studio/Data Studio using BigQuery as the data source. I came up with two screens: Executive Dashboard: Having typical metrics: Views, Transactions, Average Order Value, etc. Something you might have seen hundreds of times. Customer Journey Explorer: It lets you select a certain visitor and find out what activities he has performed within the date range. This makes it much simpler to track how one…
-
-
I Built a Self-Hosted Instagram DM Automation Platform for Creators and Small Businesses Using n8n
Most influencers, creators, and professionals use Instagram to offer some service or product to their audience. In order to attract a wider audience, these individuals write a certain keyword at the end of their post(e.g., INTERESTED) and ask their audience to mention that keyword to avail themselves of the offer. Oftentimes, it has been observed that they are not able to reply to each and every person individually due to the influx of comments. Impatient commenters start leaving negative or abusive comments without realizing that it is humanly impossible to DM hundreds of commenters within a short span of time. Meet DMPilot, a self-hosted Instagram DM Automation platform for individuals,…
-
Implementing Browser and Server Side Tracking on Shopify Using GTM and Meta CAPI
A few months back, a friend of mine who runs multiple online stores called me after a long time. After the usual chit-chat, I asked about how his online sites were doing. He told me that he had recently started a new site; his first time on Shopify and running Ad campaigns did not yield any results. Previously, he had used OpenCart and WooCommerce for other sites. Around February/March, I had completed a course on implementing website tracking, with a particular focus on server-side tracking using Google Analytics 4 (GA4), Google Tag Manager (GTM), and Stape. Since I was looking for an opportunity to apply what I had learned in…
-
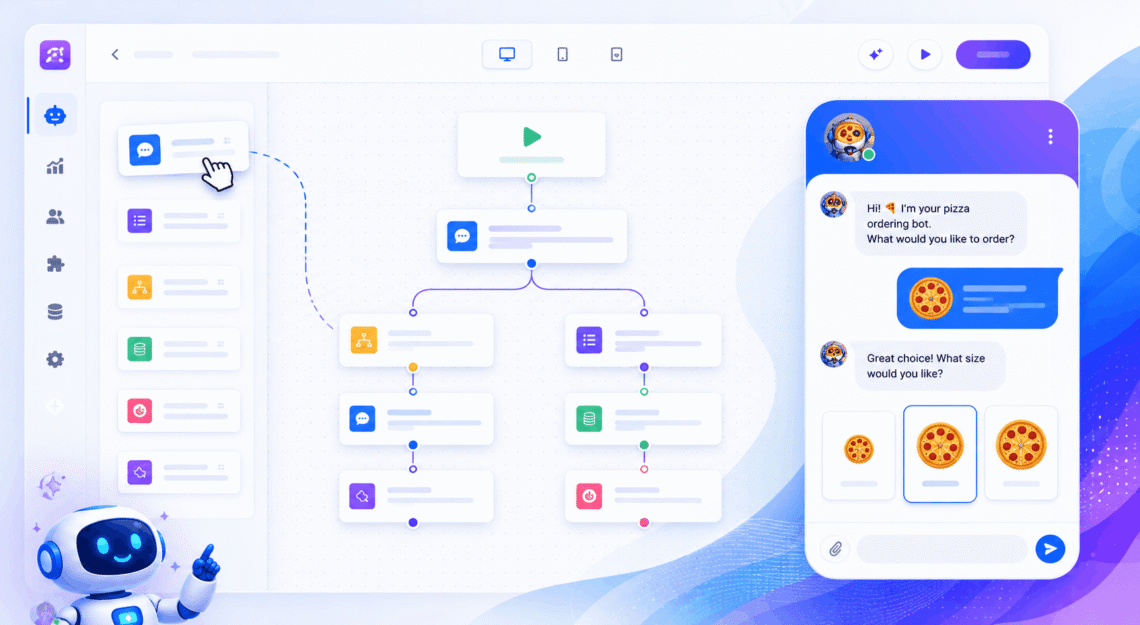
Build your first chatbot in Voiceflow
This post is part of the Voiceflow Series Chatbots have become a common part of modern businesses. Companies use them to answer customer questions, collect leads, assist with online purchases, schedule appointments, and much more. Their conversational nature makes it easier for users to get the information they need quickly, often reducing response times and improving the overall customer experience. As a result, chatbots have become an effective way for businesses to engage with visitors while automating repetitive interactions. There are many chatbot platforms and frameworks available today, but I personally recommend Voiceflow because of its simplicity and, to be honest, it just works. To keep things simple, we’ll build…
-
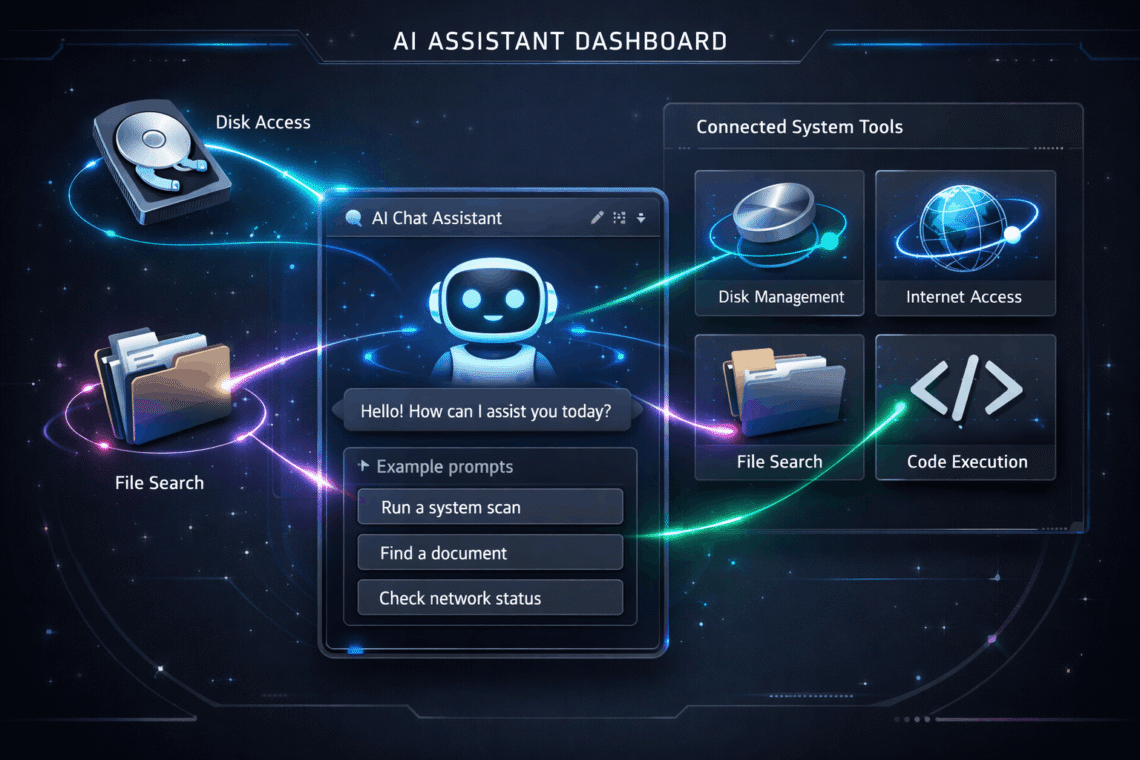
Gemini Function Calling Explained with Python (Step-by-Step Guide)
Learn how to use Gemini API Function Calling with Python to build a real AI assistant that checks system status, internet connectivity, and finds files automaticallyThis post is part of the GenAI Series. Gemini Function Calling takes AI from just answering questions to actually getting things done. In this tutorial, I will use the Gemini API with Python to build a simple but surprisingly capable AI assistant. It can check your system status, test internet connectivity, and hunt down files on your machine. This real-world example will help you understand how AI function calls work under the hood. You will also learn how to wire up external tools with Google Gemini and how modern LLMs execute actions instead of just generating text. Introduction What is Gemini Function Calling Function Calling is a way for Gemini…
-
I Built an AI Tool to Analyze Delayed Support Tickets
This post is part of the GenAI Series. A few moons ago, I built a small AI tool to deal with ticket delays at my company. It wasn’t a big, fancy product. It started as a simple experiment, but it worked really well. We were getting negative feedback from clients about tickets not being completed on time. The real challenge was figuring out the actual reason behind each delay. Was it something our team did wrong, or was the delay coming from the client’s end? When you have a ticket with huge comment threads and internal notes, it becomes difficult to go through everything to find the real reason. It takes…
-
Reimagining Customer Support with GenAI
This post is part of the GenAI Series. If you’ve ever worked in customer support, you know the feeling. It’s 2 PM on a Wednesday. Your inbox is overflowing. A customer just sent their third “following up” email. Your manager wants to know why last week’s tickets are still open. And somewhere in the back of your mind, you’re wondering: Why does this feel so hard? Here’s the thing: Most support teams aren’t failing because people aren’t trying hard enough. They’re struggling because the systems we’ve built over years of “making do” were never designed to handle today’s volume, complexity, or customer expectations. And the stakes? They’ve never been higher. According…
-
How to Implement Guardrails in LLMs (With Practical Examples)
This post is part of the GenAI Series. In March, I received an email from the founder of a website who had created an AI wrapper related to the medical field. He sent me an unsolicited email and subscribed me to his newsletter. I responded to him instantly and asked where he had gotten my email from, but I received no reply. Then I started exploring his website. The first thing I tried was asking it to create a Python code — and it did! I then sent him the following email: As you can see, I responded with the screenshot attached: Guys! The first rule for writing a GPT wrapper…
-
Building Your First Multi-Signal Trading Strategy with RSI and Moving Averages
This post is part of the T4p Series. So in this post, we are going to combine two indicators: RSI and Moving Averages to come up with a strategy. But first, let’s talk about what we mean by a “strategy.” A trading strategy is simply a set of rules that tells you when to buy and when to sell. It’s different from just using individual indicators because it combines multiple signals into a complete system. Whether you use a single indicator or a set of indicators, in the end, we are going to generate buy/sell signals or open long/short positions. When you rely on a single indicator, for instance, RSI alone,…
-
Building an AI-Powered Amazon Ad Copy Generator with Flask and Gemini
This post is part of the GenAI Series. Back-to-back GenAI-related posts, but I could not resist writing this post instead of a trading-related one. A few days ago, I built a small tool that lets you input an Amazon ASIN and instantly generate marketing copy, including Facebook ads, Amazon A+ content, and SEO product descriptions by using Gemini. The frontend is built with Bootstrap + jQuery, and the backend runs on Python Flask. While this was originally aimed at Amazon sellers, it turned out to be a fun exercise in prompt engineering, tool chaining, and turning structured product data into persuasive, persona-targeted content. If you are in a hurry, then watch…