
This post is the part of Data Engineering Series.
In the previous post, I discussed Apache Airflow and it’s basic concepts, configuration, and usage. In this post, I am going to discuss how can you schedule your web scrapers with help of Apache Airflow.
I will be using the same example I used in Apache Kafka and Elastic Search example that is scraping https://allrecipes.com because the purpose is to use Airflow. In case you want to learn about scraping you may check the entire series here.
So, we will work on a workflow consist of tasks:
- parse_recipes: It will parse individual recipes.
- download_image: It downloads recipe image.
- store_data: Finally store image and parsed data into MySQL
I will not be covering how to schedule DAGs and other things as I already covered in Part 1.
![]()
I set load_examples=False in airflow.cfg to declutter the interface and keep relevant entries here. The basic code structure look like below:
import datetime as dt
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
def parse_recipes():
return 'parse_recipes'
def download_image():
return 'download_image'
def store_data():
return 'store_data'
default_args = {
'owner': 'airflow',
'start_date': dt.datetime(2018, 10, 1, 10, 00, 00),
'concurrency': 1,
'retries': 0
}
with DAG('parsing_recipes',
catchup=False,
default_args=default_args,
schedule_interval='*/10 * * * *',
# schedule_interval=None,
) as dag:
opr_parse_recipes = PythonOperator(task_id='parse_recipes',
python_callable=parse_recipes)
opr_download_image = PythonOperator(task_id='download_image',
python_callable=download_image)
opr_store_data = PythonOperator(task_id='store_data',
python_callable=store_data)
opr_parse_recipes >> opr_download_image >> opr_store_data
If you register this DAG by running airflow scheduler something similar should appear on your screen.
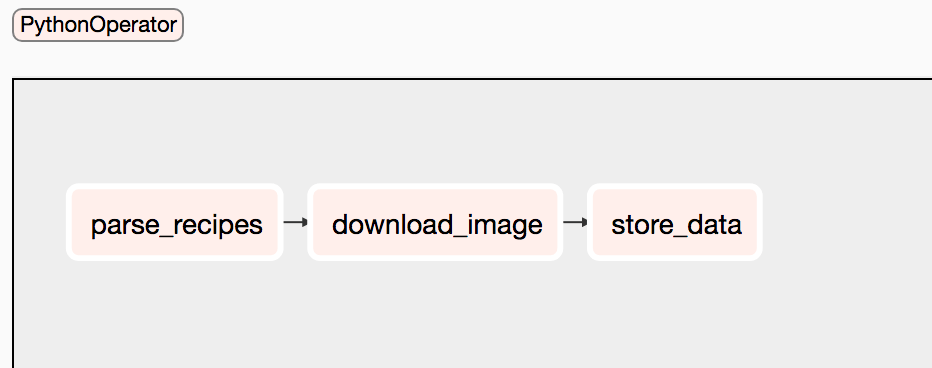
You can see the power of workflows here. You just come up with a skeleton and can rush to your higher-ups and show how their enterprise data pipeline will look like without getting into details first. Cool, right?
Now, let’s implement each task routine one by one. Before I get into the original logic of parse_recipies, allow me to discuss how Airflow tasks can communicate with each other.
What is XCOM?
XCOM provides a way to let tasks communicate with each other. The pushed data from one task is pulled into another task. If you set provide_context=True, the returned value of the function is pushed itself into XCOM which itself is nothing but a Db table. If you check airflow.db you will find a table with name xcom you will see entries of the running task instances.
def parse_recipes(**kwargs):
return 'RETURNS parse_recipes'
def download_image(**kwargs):
ti = kwargs['ti']
v1 = ti.xcom_pull(key=None, task_ids='parse_recipes')
print('Printing Task 1 values in Download_image')
print(v1)
return 'download_image'
The first task has no such changes other than providing **kwargs which let share key/value pairs. The other is setting provide_context=True in each operator to make it XCom compatible. For instance:
opr_parse_recipes = PythonOperator(task_id='parse_recipes',
python_callable=parse_recipes, provide_context=True)
The download_image will have the following changes:
def download_image(**kwargs):
ti = kwargs['ti']
v1 = ti.xcom_pull(key=None, task_ids='parse_recipes')
print('Printing Task 1 values in Download_image')
print(v1)
return 'download_image'
The first line is ti=kwargs['t1']` get the instances details by access ti key. In case you wonder why this has been done. If you print kwargs it prints something like below in which you can find keys like t1, task_instance etc to get a task’s pushed value:
{
'dag': <DAG: parsing_recipes>,
'ds': '2018-10-02',
'next_ds': '2018-10-02',
'prev_ds': '2018-10-02',
'ds_nodash': '20181002',
'ts': '2018-10-02T09:56:05.289457+00:00',
'ts_nodash': '20181002T095605.289457+0000',
'yesterday_ds': '2018-10-01',
'yesterday_ds_nodash': '20181001',
'tomorrow_ds': '2018-10-03',
'tomorrow_ds_nodash': '20181003',
'END_DATE': '2018-10-02',
'end_date': '2018-10-02',
'dag_run': <DagRunparsing_recipes@2018-10-0209: 56: 05.289457+00: 00: manual__2018-10-02T09: 56: 05.289457+00: 00,
externallytriggered: True>,
'run_id': 'manual__2018-10-02T09:56:05.289457+00:00',
'execution_date': <Pendulum[
2018-10-02T09: 56: 05.289457+00: 00
]>,
'prev_execution_date': datetime.datetime(2018,
10,
2,
9,
56,
tzinfo=<TimezoneInfo[
UTC,
GMT,
+00: 00: 00,
STD
]>),
'next_execution_date': datetime.datetime(2018,
10,
2,
9,
58,
tzinfo=<TimezoneInfo[
UTC,
GMT,
+00: 00: 00,
STD
]>),
'latest_date': '2018-10-02',
'macros': <module'airflow.macros'from'/anaconda3/anaconda/lib/python3.6/site-packages/airflow/macros/__init__.py'>,
'params': {
},
'tables': None,
'task': <Task(PythonOperator): download_image>,
'task_instance': <TaskInstance: parsing_recipes.download_image2018-10-02T09: 56: 05.289457+00: 00[
running
]>,
'ti': <TaskInstance: parsing_recipes.download_image2018-10-02T09: 56: 05.289457+00: 00[
running
]>,
'task_instance_key_str': 'parsing_recipes__download_image__20181002',
'conf': <module'airflow.configuration'from'/anaconda3/anaconda/lib/python3.6/site-packages/airflow/configuration.py'>,
'test_mode': False,
'var': {
'value': None,
'json': None
},
'inlets': [
],
'outlets': [
],
'templates_dict': None
}
The next, I called xcom_pull to put the certain task’s returned value. In my the task id is parse_recipes:
v1 = ti.xcom_pull(key=None, task_ids='parse_recipes')
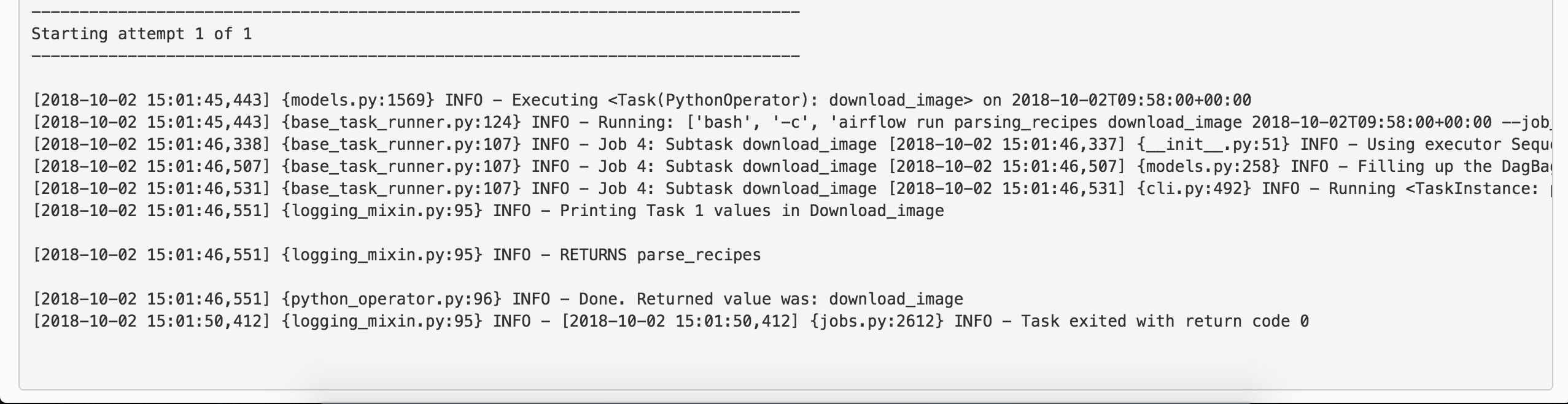
As you can see in the screenshot above, it is printing the returned value as {logging_mixin.py:95} INFO - RETURNS parse_recipes
Alright, you learned the concept of XCOM, now revert back to our original code.
So the idea is, the first task will read URLs from the text file(You can create another task that will only be responsible to fetch links and store in File or DB. That’s your Task!) and then that list of entries is passed to next task to download images and add the info of newly downloaded file in the dict and finally store it into MySQL.
download_image will now look like below:
def download_image(**kwargs):
local_image_file = None
idx = 0
records = []
ti = kwargs['ti']
parsed_records = ti.xcom_pull(key=None, task_ids='parse_recipes')
for rec in parsed_records:
idx += 1
image_url = rec['image_url']
r_url = rec['url']
print('Downloading Pic# {}'.format(idx))
local_image_file = dl_img(image_url, r_url)
rec['local_image'] = local_image_file
records.append(rec)
return records
I am not discussing dl_img method as this is beyond the scope of this post. You can check the code on the Github for it. Once the file is downloaded, you append the key in the original record.
The store_data now looks like below:
def store_data(**kwargs):
ti = kwargs['ti']
parsed_records = ti.xcom_pull(key=None, task_ids='download_image')
print('PRINTING DUMPED RECORDS in STORE DATA')
print(parsed_records)
return 'store_data'
Make sure you set provide_context=True in opr_store_data operator otherwise you will get the following error:
Subtask store_data KeyError: 'ti'
Now, the data is available. All is left to store data into MySQL.
To use MySQL with Airflow, we will be using Hooks provided by Airflow.
Airflow Hooks let you interact with external systems: Email, S3, Databases, and various others.
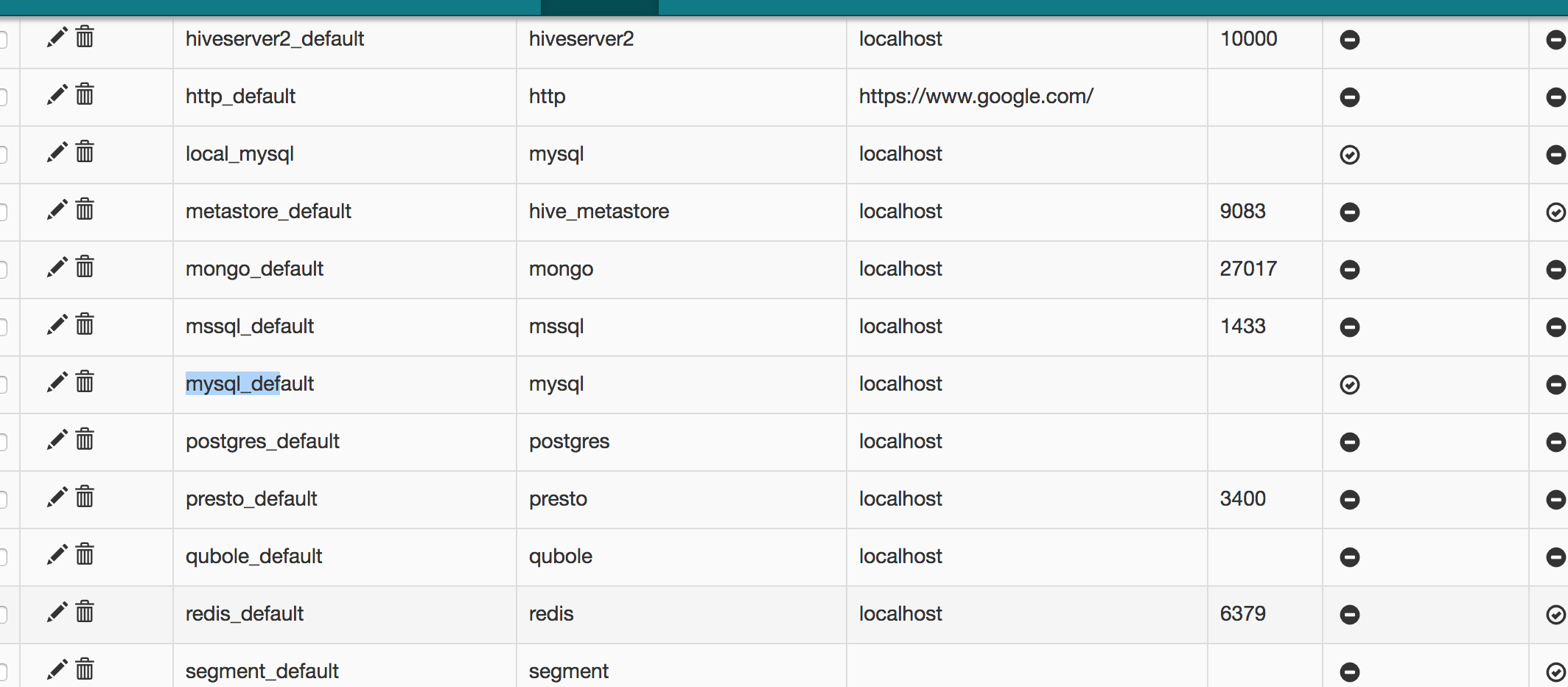
Before we get into coding, we need to set up a MySQL connection.
On Airflow Web UI go to Admin > Connections. Here you will see a list of existing connections if you go to http://0.0.0.0:8080/admin/connection/
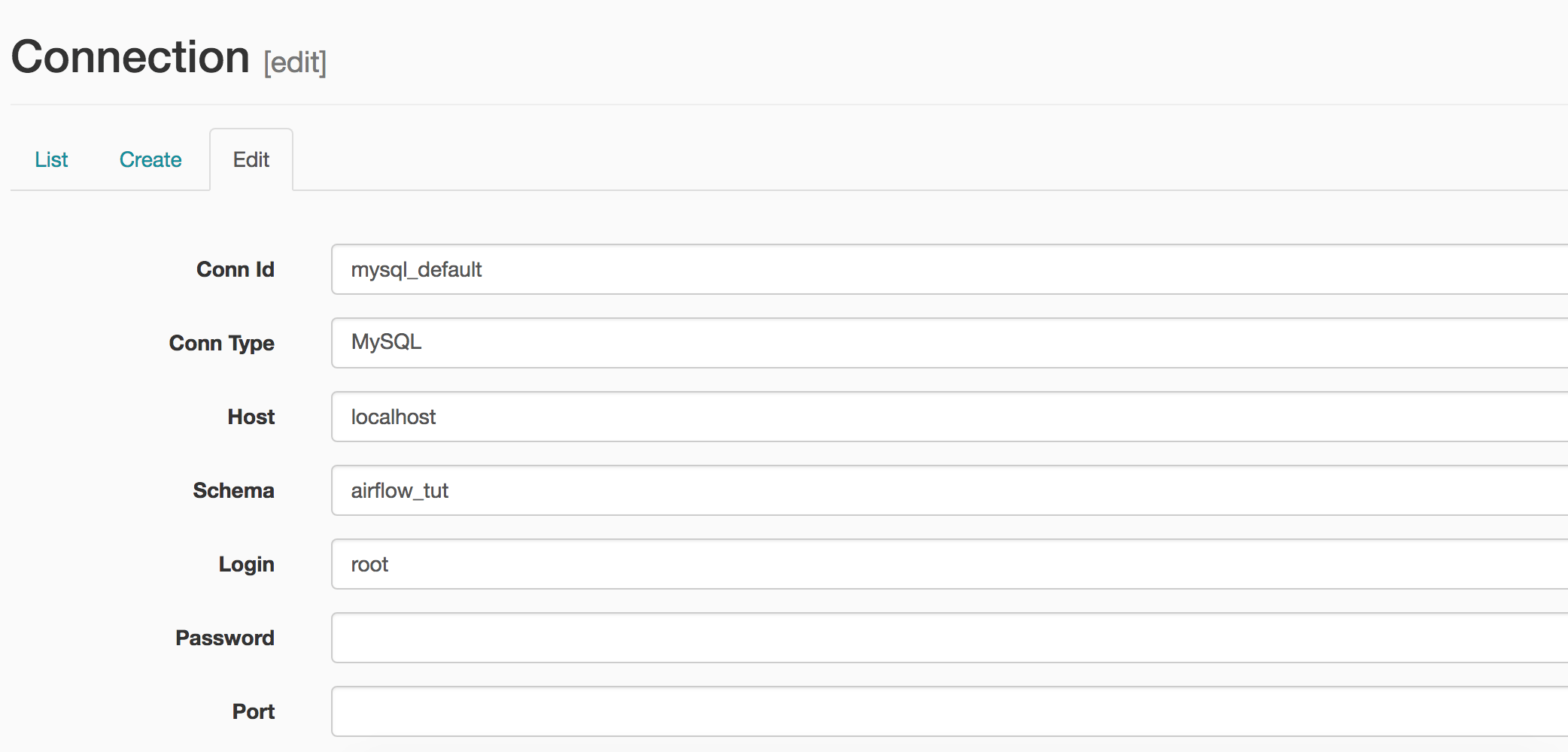
I edit the connection and set the table name and password.
 I will be importing
I will be importing MySqlHook to use MySQL library
from airflow.hooks.mysql_hook import MySqlHook
def store_data(**kwargs):
ti = kwargs['ti']
parsed_records = ti.xcom_pull(key=None, task_ids='download_image')
connection = MySqlHook(mysql_conn_id='mysql_default')
for r in parsed_records:
url = r['url']
data = json.dumps(r)
sql = 'INSERT INTO recipes(url,data) VALUES (%s,%s)'
connection.run(sql, autocommit=True, parameters=(url, data))
return True
The SQL of the table is given below
CREATE TABLE recipes ( `id` int(11) UNSIGNED NOT NULL AUTO_INCREMENT, `url` varchar(100) NOT NULL, `data` text NOT NULL, PRIMARY KEY (`id`) );
That’s it. Oh, wait… what if Admin can be notified that the workflow is successfully done? Airflow let you use EmailOperator for the purpose.
opr_email = EmailOperator(
task_id='send_email',
to='jon@yahoo.com',
subject='Airflow Finished',
html_content=""" <h3>DONE</h3> """,
dag=dag
)
Before using it you gotta make changes in airflow.cfg for mail related settings. There is an [smtp] section
[smtp] # If you want airflow to send emails on retries, failure, and you want to use # the airflow.utils.email.send_email_smtp function, you have to configure an # smtp server here smtp_host = smtp.gmail.com smtp_starttls = False smtp_ssl = True # Uncomment and set the user/pass settings if you want to use SMTP AUTH smtp_user = user@gmail.com smtp_password = your_password smtp_port = 465 smtp_mail_from = user@gmail.com
I used my own Gmail account to send mail.
Conclusion
In this post, you learned how to introduce Airflow in your existing scraping architecture and how to use MySQL with Airflow. There are various possibilities to improve it or extend it. Try it and let me know.
The code is available on Github
When you run scrapers, there is a high chance of getting blocked and you get no choice but to wait and pray you to get unblocked. Proxy IP addresses are used to avoid such circumstances. The company I work at uses OxyLabs proxies. I can’t recommend them enough for your daily usage. Click here to visit and get registered!
Planning to write a book about Web Scraping in Python. Click here to give your feedback
Related posts:
 Getting started with Apache Airflow
Create your first ETL in Luigi
Getting started with Apache Airflow
Create your first ETL in Luigi An introductory tutorial covering the basics of Luigi and an example ETL application.
 Create your first ETL Pipeline in Apache Spark and Python
Create your first ETL Pipeline in Apache Spark and Python
 Create your first ETL Pipeline in Apache Beam and Python
Create your first ETL Pipeline in Apache Beam and Python Learn how to use Apache Beam to create efficient Pipelines for your applications.