
TLDR: Visit Github repo if you are not interested in the internals of the lib.
Today I present you another library I made in Go language, called, Fehrist
From the Github README:
Fehrist is a pure Go library for indexing different types of documents. Currently, it supports only CSV and JSON but flexible architecture gives you the liberty to add more documents. Fehrist(فہرست) is an Urdu word for Index. Similar terminologies used in Arabic(فھرس) and Farsi(فہرست) as well.
Fehrist is based on an Inverted Index data structure for indexing purposes.
Why did I make it?
It seems I have fallen in love with Golang after Python. Go is an opinionated language that does not let you get distracted in various small decisions. The reason for making this particular lib is nothing but learning about indexing; how it works and what algorithms are available. I picked the Inverted Index due to its flexibility and relatively easier implemented than others like B+Trees. I also took inspiration from ElasticSearch for writing and arranging index files on disk.
How it Works?
As I mentioned that it is based on an inverted index. All files, regardless of their type are tokenized after the first stage where a DOCID is assigned to each record. A record is a single entry in the case of CSV, JSON, or XML file. After the assignment of DOCID, it is then tokenized where each term in the file is mapped corresponding DOCID and the file name. The successful indexed document(s) can then be searched by providing a keyword. The output of the search result is a JSON structure. Golang maps data structure has been used for intermediate data processing and searching. Below is the diagram that might help you to understand the entire process of indexing.
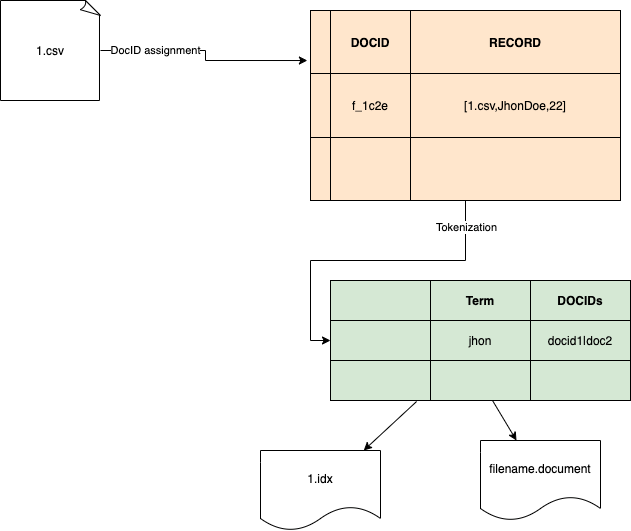
In the first step, the CSV file was fed to the system which was then split record-wise and mapped with a DOCID. In the second step, each record was tokenized into each term in a way that it was mapped with the count of occurrence. For instance, Jhon was found in documents 1.csv and 2.csv, it will create a pipe-delimited structure which is then assigned as an individual entry of the map against its corresponding key. As you can in the diagram above, john was found in DOCIDs docid1 and docid2. Go maps have been used for the purpose.
Finally, the data is saved into the disk. I stole the idea from ElasticSearch for the data management on disk:
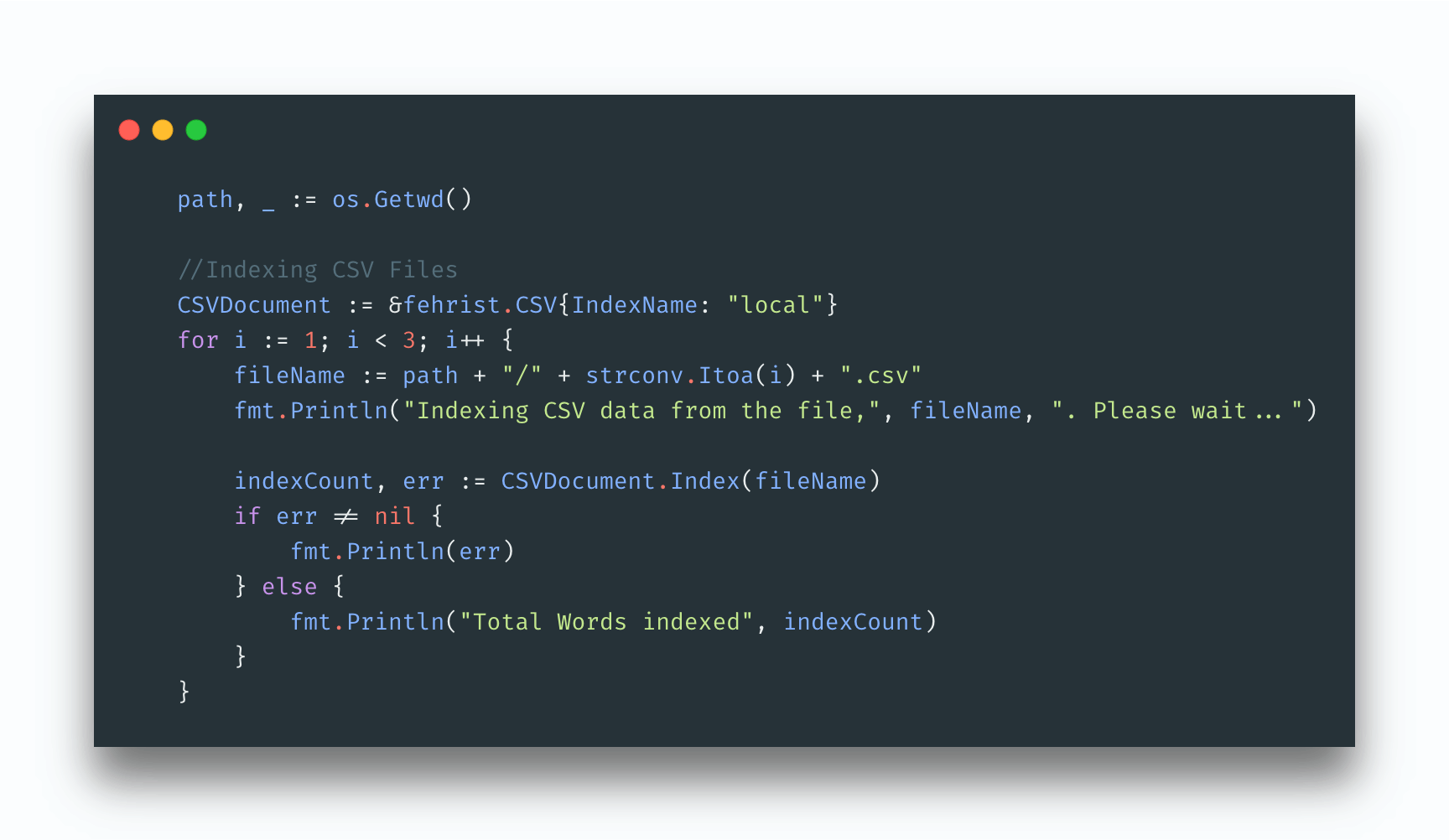
As you can in the picture above, each index file is saved as .idx file. At first it created a folder of the name you had provided. All relevant files are then stored in it(Thanks ElasticSearch for giving me this idea). You are also seeing files with extension .document which is actually originally entries along with their DOCIds. All data is then serialized with the help of MessagePack. Below is the code that is indexing CSV files.
The library is flexible. Thanks to polymorphism provided by Go, you can extend this library very easily by implementing a couple of methods.
Searching is then easy:
The `Search` method takes an index name as a parameter because a folder was created of the same name and all files were stored in it. Init() method was used to pull all the data from documents and indices in maps.
As I said it is a flexible lib. All you need to add your own document type struct just like I have done for JSON and CSV.

Conclusion
I hope you like this post and will use this library in your next projects. There are a few things that it does not cover like full search. It also does not apply stemming and stop words either. For now, it returns data based on the exact keyword found. You are free to enhance it by forking it. You can download this lib from Github.
Header Photo by Maksym Kaharlytskyi on Unsplash


