I wrote about ScrapingBee a couple of years ago, where I gave a brief intro about the service. ScrapingBee is a cloud-based scraping service that provides both headless and lightweight, typical HTTP request-based scraping services.
Recently, I discovered that they are providing some cool features that other online services are not providing as such. What are those features? I thought to explore and explain them with a real use case. I used Python to automate the Daraz group’s shopping website, a famous e-commerce website service in Asian countries like Pakistan, Nepal, Bangladesh, and Sri Lanka. I am automating DarazPK since I am in Pakistan. You can view the demo below:
What is an Automated Buying Bot and How Does It Work?
An automated buying bot is a script that mimics human shopping behavior; logging in, browsing a product page, adding items to a cart, and placing an order, without any manual input. Instead of clicking through a website yourself, you write code that does it for you.
These bots are commonly used for price-drop automation, flash sale sniping, inventory monitoring, and QA testing of e-commerce checkout flows. In this tutorial, we will build one in Python that can log into an e-commerce site, navigate to a product, and complete a purchase, all via ScrapingBee’s cloud headless browser, with no Selenium installation required.
Why ScrapingBee Instead of Selenium for Buying Bots?
The reason I am using ScrapingBee is simple. First, it provides proxies so I do not have to worry about getting blocked. Second, they provide a cloud-based headless browser. What I am going to do could easily be done via Selenium as well, but deploying a Selenium-based solution and that too with proxies is not something that is easy, plus you gotta have your own EC2 instance or some other to run this service 24×7. Since I am using a REST API-based service, I could simply incorporate it into my shared hosting by using PHP(ScrapingBee can be implemented in ANY language that supports HTTP requests.). While these services are being provided by other services as well, like ScraperAPI which I discussed here. The thing that differentiates them from others is that they also provide the facility to interact with DOM via Clicks and Input values, something that is a hallmark of Selenium and many of us have already used it. This is a very exciting feature, it means now I can log in to a website, do some activities and fetch my required info and quit. All without installing a single piece of extra software at my end. In past, I have automated Amazon shopping with requests and Beautifulsoup(yeah, it’s pretty hard, fetching cooked and sending over to subsequent requests.) but it is easier if you use a library like Selenium. With the help of ScrapingBee, I could automate my entire shopping experience without any hassle in Python.
Alright! So the goal is that I have to automate buying an Item from DarazPK. This is the typical workflow:
- I will log in via my credentials.
- Add an item to the cart
- Select the payment method
- Proceed to checkout.
- Fetch the order number
Development Setup
There is no such development setup. All I did was install the ScrapingBee library pip install scrapingbee
It is not necessary. You can rely on requests library as well. Since I am demonstrating a service’s features, I installed it; otherwise, it is pretty easy to do without installing any extra library.
It is not necessary but I am also installing python-dotenv library because I will be using .env file to store API and other secrets. You should too!
pip install python-dotenv
OK! So all things are ready. The item I want to buy is this, some random item I found on the site. I also wanted to make sure that the delivery time is long so that I could cancel the item. After all, it is all for development purposes! The very first thing I am going to do is to create an .env file.
EMAIL=<YOUR DARAZ EMAIL> PASSWORD=<YOUR DARAZ PASSWORD> API_KEY=<SCRAPINGBEE API KEY>
After you mentioned your credentials, it’s time to start coding. The very first few things I did was importing libraries and define variables.
from dotenv import load_dotenv
import os
if __name__ == '__main__':
load_dotenv()
EMAIL = os.environ.get('EMAIL')
SESSION_ID = 123456 # To keep the IP Same during the transitions.
PASSWORD = os.environ.get('PASSWORD')
API_KEY = os.environ.get('API_KEY')
LOGIN_URL = 'https://member.daraz.pk/user/login'
PRODUCT_URL = 'https://www.daraz.pk/products/fridge-toy-for-girls-kitchen-toy-set-for-kids-fridge-with-fridge-accessories-toy-for-girls-i152820734-s1317422364.html'
After pulling data from environment variables and URLs for the login and product page, I am setting a value for SESSION_ID variable. When you assign a session value for each request, you are assigned the same IP address for the next 5 minutes. We are assigning the same session value because we want to let the site know that a single person is visiting this website from his/her computer. To learn more about session IDs, visit here.
Next, I am going to create the ScrapingBee client object by passing the API_KEY.
client = ScrapingBeeClient(api_key=API_KEY)
As per our plan, the first step is to log in. When you visit the login page and inspect the login/password fields, they look like the below:
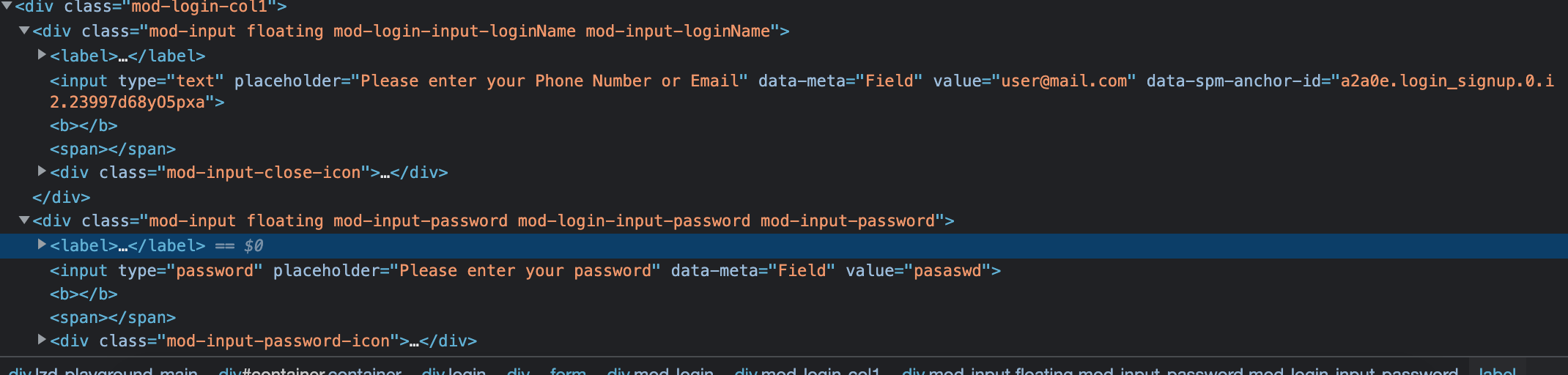
This helps to find out our selectors. Let’s make our first attempt to access these fields.
def login():
cookie_string = None
client = ScrapingBeeClient(api_key=API_KEY)
email_selector = 'input[data-meta="Field"][type="text"]'
password_selector = 'input[data-meta="Field"][type="password"]'
response = client.get(
LOGIN_URL,
params={
'screenshot': True,
'json_response': True,
'session_id': SESSION_ID,
'js_scenario': {"instructions": [
{"wait_for": email_selector},
{"fill": [email_selector, EMAIL]},
{"wait": 9000}
]
},
}
)
if not response.ok:
print("Login request has failed, please try again")
print('Response HTTP Status Code: ', response.status_code)
print('Response Content: ', response.content)
return False, cookie_string
data = response.json()
with open("login_screen_final.png", "wb") as f:
f.write(base64.b64decode(data["screenshot"]))
Lots of things are happening here. After creating the client object of ScrapingBee, I am assigning the CSS selectors for email and password. In client.get() method I am passing the URL that is going to be accessed, in our case, it is the login URL, and then a dictionary object as a params parameter with multiple fields. The very first is used to decide whether you want to take a screenshot of the page you are going to access. If you have worked on Selenium, then this is something similar to driver.save_screenshot() method. The next decides whether you need the returned data in JSON format or not. If it is true, it returns a big JSON payload that contains the HTML of the page, headers, cookies, screenshot data in base64 format, and other things. By default, it returns the HTML only. Since I wanted the screenshot data and other fields, I set JSON to True here. Visit here to learn more about it. Next is js_scenario. Actually, it is ScrapingBee’s way to tell their system what to do when visiting the page or pages. For instance, you are writing a script that visits a page, clicks a button, navigates to another page, and then fills the form field and submits it. You can pass all these instructions once in the order they should be executed. Just make sure it should not take more than 40 seconds to avoid timeouts. To learn more about it visit the documentation.
So my instructions set is to wait for the selector to become visible, fill it, and then wait for 4 seconds to let it complete. Next, I am checking whether the request was successful or not, and then save the returned screenshot data in an image file. If all goes well, it shows this:

Pretty cool, no? It accessed the page, filled in the email field, took the screenshot, and quit. In my view, taking screenshots is the best way to debug the outcome. It also returns the returned HTML, so you can use that for debugging as well. Below is the complete code of login routine.
def login():
cookie_string = ''
email_selector = 'input[data-meta="Field"][type="text"]'
password_selector = 'input[data-meta="Field"][type="password"]'
button_selector = 'button[type="submit"]'
response = client.get(
LOGIN_URL,
params={
'screenshot': True,
'json_response': True,
'session_id': SESSION_ID,
'js_scenario': {"instructions": [
{"wait_for": email_selector},
{"fill": [email_selector, EMAIL]},
{"fill": [password_selector, PASSWORD]},
{"click": button_selector},
{"wait": 9000}
]
},
}
)
if not response.ok:
print("Login request has failed, please try again")
print('Response HTTP Status Code: ', response.status_code)
print('Response Content: ', response.content)
return False, cookie_string
data = response.json()
cookies = data['cookies']
cookies_to_send = dict()
for cookie in cookies:
if cookie['name'] in ["lzd_b_csg", "_tb_token_", "lzd_sid"]:
cookies_to_send[cookie['name']] = cookie['value']
# Certain Login cookies required
if len(cookies_to_send) < 1:
print("The cookies lzd_b_csg, _tb_token_ and lzd_sid were not found, please try again")
exit()
for key in cookies_to_send:
cookie_string += "{}={},domain=.daraz.pk;".format(key, cookies_to_send[key])
cookie_string = cookie_string.rstrip(';')
with open("login_screen_final.png", "wb") as f:
f.write(base64.b64decode(data["screenshot"]))
return True, cookie_string
So I am passing instructions to fill out the form and click the button. If all goes well, you will see the following screen. I have hidden my personal details. Cookie data is being returned, which I have to use for future requests to stay logged in.

Alright! So far so good. Now the next and most important step is to visit the product page and buy. So this is how I start buy_item() routine.
def buy_item(cookies_string):
buy_now_button = 'button[class="add-to-cart-buy-now-btn"]'
buy_now_button = '.add-to-cart-buy-now-btn'
process_buy = '.checkout-order-total-button'
cod_method = '#automation-payment-method-item-122'
place_order = '.btn-place-order'
response = client.get(
PRODUCT_URL,
params={
'screenshot': True,
'json_response': True,
'session_id': SESSION_ID,
"wait": 6000,
"cookies": cookies_string,
'js_scenario': {"instructions": [
{"wait_for": buy_now_button},
{"wait": 8000},
]
},
}
)
if response.ok:
d = json.loads(response.content)
with open("screenshot_product_final.png", "wb") as f:
f.write(base64.b64decode(d["screenshot"]))
else:
print('Response HTTP Status Code: ', response.status_code)
print('DATA: ', response.content)
As you can see, I am passing the cookie string I fetched from login() routine. The reason for this is that Daraz only allows you to buy products if you are a member. I am doing nothing fancy here; waiting for the BUY NOW appearance and quitting after 8 seconds. This wait could vary as per the site you are accessing and the ScrapingBee network itself. If all goes well, you see the following page: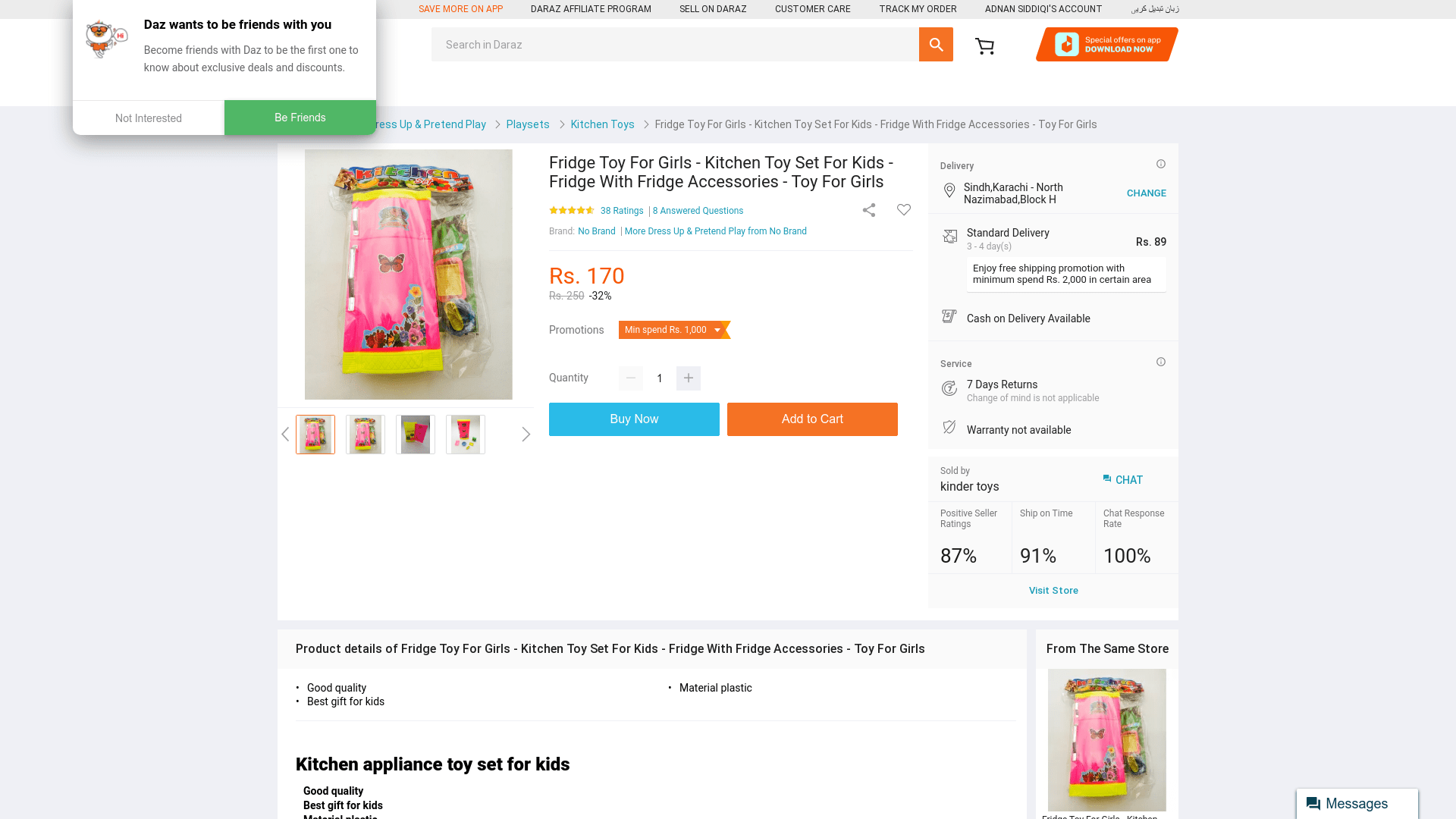
See the top, you see I appear as logged in. For this very reason, I am passing the cookies. The complete instructions set from clicking the Buy Now button to fetch the order number are given below.
response = client.get(
PRODUCT_URL,
params={
'extract_rules': {"order_number": ".thank-you-order-number"},
'screenshot': True,
'json_response': True,
'session_id': SESSION_ID,
"wait": 6000,
"cookies": cookies_string,
'js_scenario': {"instructions": [
{"wait_for": buy_now_button},
{"click": buy_now_button},
{"wait_for": process_buy},
{"click": process_buy},
{"wait": 1000},
{"wait_for": cod_method},
{"click": cod_method},
{"wait_for": place_order},
{"click": place_order},
{"wait": 8000},
]
},
}
)
After waiting for the Buy Now button, it is clicked. Then I wait for the availability of the Check Out button, I am waiting for a second, and then for the Payment method section, in my case it is COD(Cash on Delivery), and finally clicking the Place Order Button. And… if all goes well then…
The new thing I added is the extract_rules.
'extract_rules': {"order_number": ".thank-you-order-number"}
This is another cool feature provided by ScrapingBee. You can parse the HTML of the visited page. Do note that you can only use it on the last visited page, in my case, the order page. If the request is successfully executed, you may fetch the order_number field from the body field of the response. Visit the documentation to learn more about it.
if response.ok:
d = json.loads(response.content)
order_number = d['body']
order_number = d['body']['order_number']
print(order_number)
And of course, the final page would look like the below(The owner of this product would definitely be considering me insane as I have bought and canceled this product multiple times 😛 )
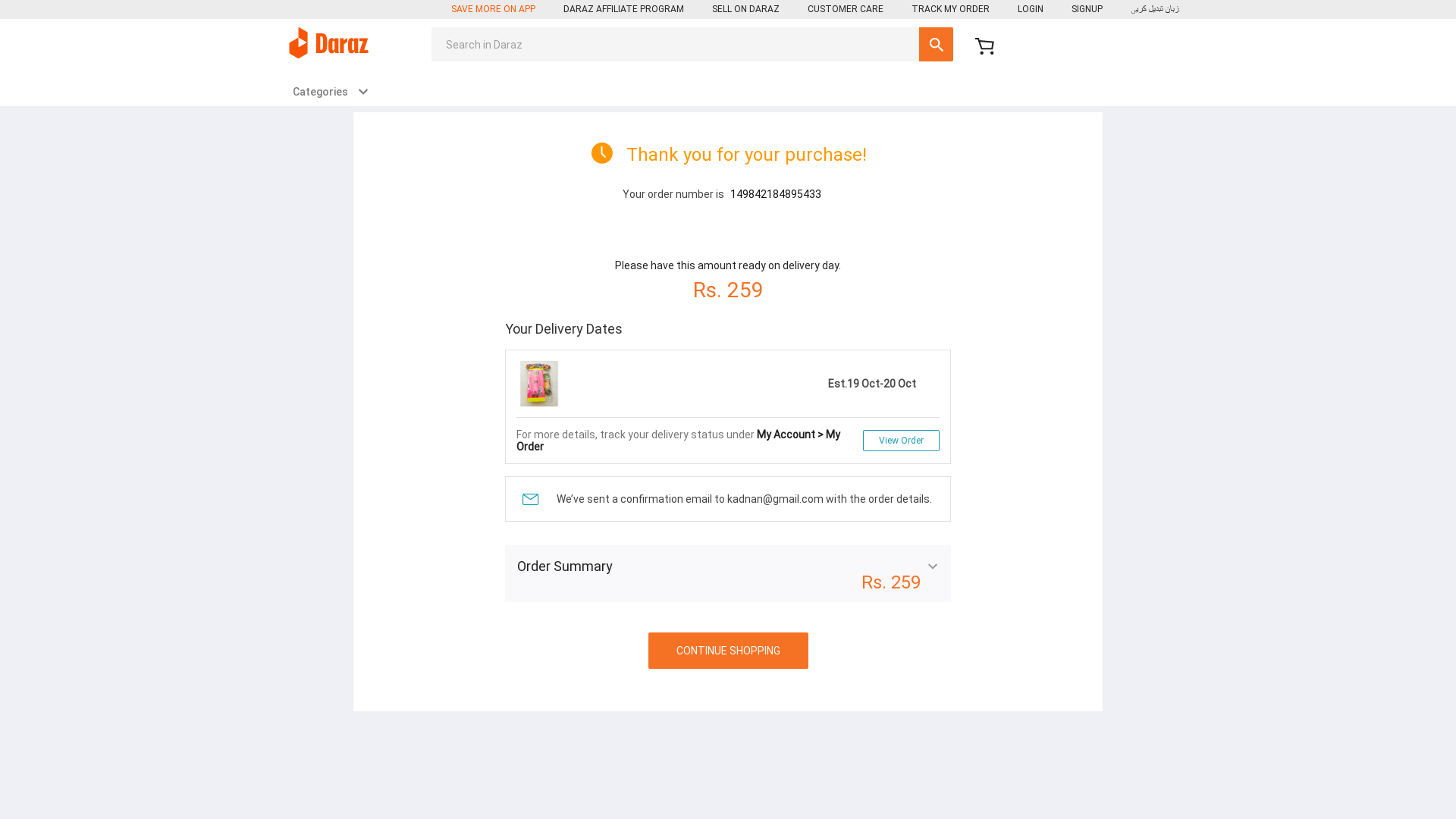
Match the order number on the page and on the image above.
Conclusion
In this post, we explored different features of ScrapingBee and how you can use it to automate complex workflows like buying an item on an e-commerce website. The best thing is that you are automatically assigned a new proxy IP without any extra effort and that too at very affordable prices. ScrapingBee provides comprehensive documentation to utilize its system for multiple purposes. Like always, the code is available on GitHub.
Special thanks to the ScrapingBee tech team, who responded to my queries whenever I got stuck.
Oh, if you sign up here with my referral link or enter promo code ADNAN, you will get a 10% discount on it. In case you do not get the discount then just let me know via email on my site, and I’d sure help you out.
Trying to automate buying something online?
If you’re exploring something similar, feel free to grab a quick 15-minute call and tell me what you’re trying to build.
Related posts:
 ScrapingBee API Python Tutorial: How to Use Render JS, Proxies & Headers
ScrapingBee API Python Tutorial: How to Use Render JS, Proxies & Headers Learn how to use cloud based Scraping API to scrape web pages without getting blocked.
 Develop AirBnb Parser in Python
Develop AirBnb Parser in Python
 Create Amazon Scraper in Python using Scraper API
Create Amazon Scraper in Python using Scraper API Learn how to create an Amazon scraper in python to scrape product details like price, ASIN etc

