In the last post of the scraping series, I showed you how you can use Scraper API, an online data extractor to scrape websites that use proxies hence your chance of getting blocked is reduced. Today I am going to show how you can use Scraper API to scrape websites that are using AJAX to render data with the help of JavaScript, Single Page Applications(SPAs), or scraping websites using frameworks like ReactJS, AngularJS, or VueJS.
I will be working on the same code I had written in the introductory post.
Let’s work on a simple example. There is a website that tells your IP, called HttpBin. If you load via browser it will tell your real IP. For instance, in my case, it returned:
{ "origin": "12.48.217.89, 12.48.47.29" }
Of course not my original IP. We will access this API via an AJAX call. What I did that I made a simple page called httpbin API via AJAX:
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Testing HTTP BIN</title>
<script src="https://cdnjs.cloudflare.com/ajax/libs/jquery/3.4.1/jquery.min.js"></script>
</head>
<body>
<h2>Know your IP</h2>
<div id="ip"></div>
<script>
$(function() {
$.get("https://httpbin.org/ip", function(data) { //$( ".result" ).html( data ); $('#ip').html(data.origin) //alert(data.origin); }); });
</script>
</body>
</html>
Save the code above in an HTML file and upload it somewhere. For the demo, I have set it up on my site and I will offload it soon so do try on your own server!
When you check the view source, you will find something like below:
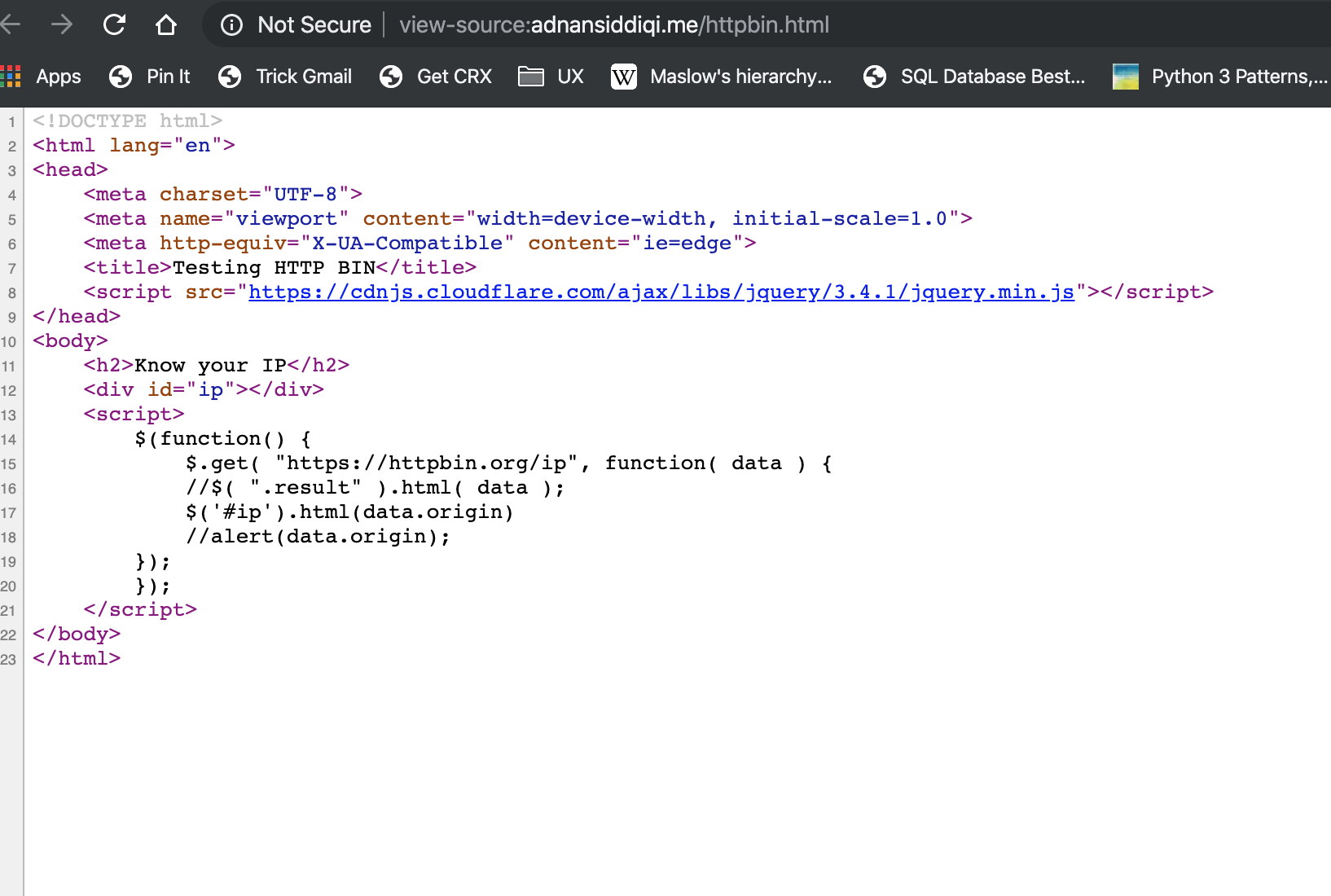
As you can see the <div> with the id ip is empty which tells you that the data is being displayed by *other means*. Now I will access the page via Scraper API.
URL_TO_SCRAPE = 'http://adnansiddiqi.me/httpbin.html'
payload = {'api_key': API_KEY, 'url': URL_TO_SCRAPE, 'render': 'true'}
r = requests.get('http://api.scraperapi.com', params=payload, timeout=60)
print(r.status_code)
html = r.text.strip()
You see this time I passed render:true and when I run it returns the following:
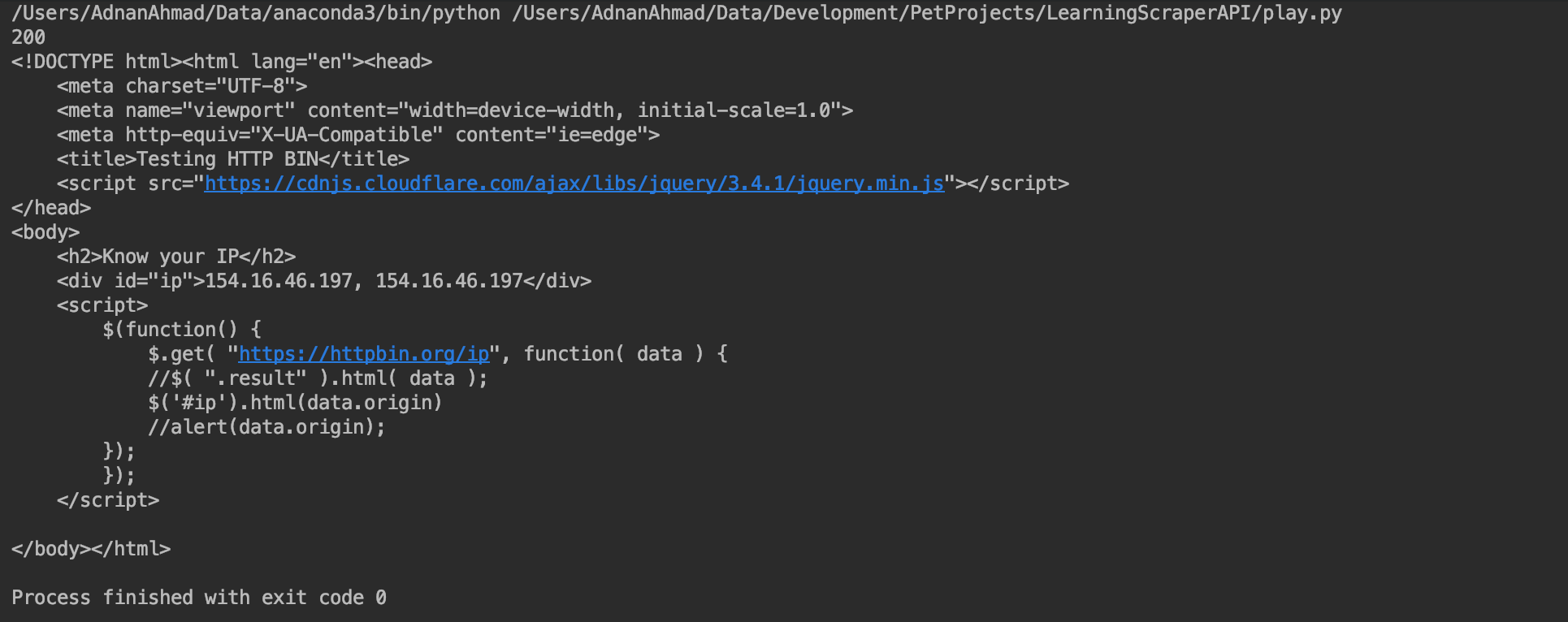
As you can see it rendered the page and returned the markup, just like a headless browser should do. The other thing you would have noticed is that it returns a random IP. At times it happens that it might return the static markup because it does not get able to load the rendered data due to network issues or something so don’t worry about it as you can try again.
Alright, it was a toy application, how about testing it out on some “real” website? I pick Cricbuzz commentary about one of the test matches played between England and Australia in the Ashes(https://www.cricbuzz.com/cricket-full-commentary/20719/eng-vs-aus-5th-test-the-ashes-2019). One of the entries about delivery is displayed below:

Search this page by opening ViewSource and you can’t find the text. The reason is that the data is loaded via an API and Javascript renders it.
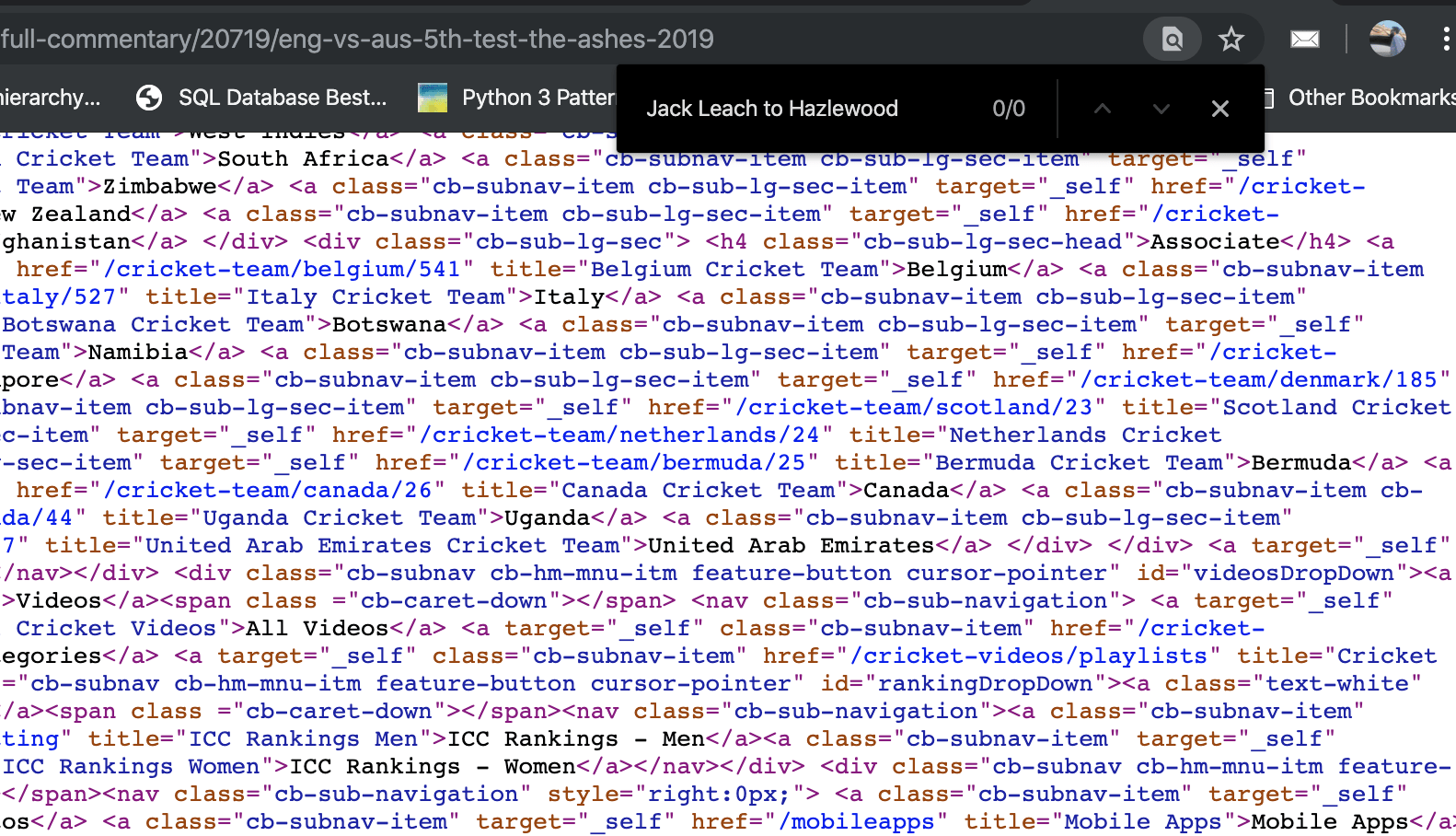
Now let’s try it with Scraper API. I just changed the value of URL_TO_SCRAPE above. Searching Jack Leach to Hazlewood and returned the following:

As you can see it’s right there!
Conclusion
In this post, you learned how easy it is to use Scraper API to crawl dynamic web pages or screen scraping of Javascript-enabled websites. You do not need to do a separate setup, no need to install and waste time for the Selenium+Web Driver setup. You can use existing knowledge and get your stuff done. All were required to set the render parameter to True. You do not have to worry about Proxy IPs either nor do you have to pay hundreds of dollars, especially when you are an individual or working in a startup. The company I work with spends 100s of dollars on a monthly basis just for the proxy IPs. Without any doubt, Scraper API is one of the best web scraping tools available in the market at an affordable cost.
Oh if you sign up here with my referral link or enter promo code adnan10, you will get a 10% discount on it. In case you do not get the discount then just let me know via email on my site and I’d sure help you out.