
This post is the part of Data Engineering Series.
In previous posts, I discussed writing ETLs in Bonobo, Spark, and Airflow. In this post, I am introducing another ETL tool which was developed by Spotify, called Luigi.
Earlier I had discussed here, here and here about writing basic ETL pipelines. Bonobo is cool for write ETL pipelines but the world is not all about writing ETL pipelines to automate things. There are other use cases in which you have to perform tasks in a certain order once or periodically. For instance:
- Monitoring Cron jobs
- transferring data from one place to another.
- Automating your DevOps operations.
- Periodically fetching data from websites and update the database for your awesome price comparison system.
- Data processing for recommendation-based systems.
- Machine Learning Pipelines.
The possibilities are endless.
Before we move on further to implement Luigi in our systems, let’s discuss what actually is Airflow and it’s terminologies.
What is Luigi?
From the Github page:
Luigi is a Python (2.7, 3.6, 3.7 tested) package that helps you build complex pipelines of batch jobs. It handles dependency resolution, workflow management, visualization, handling failures, command line integration, and much more.
Let’s learn and understand the basic components and terminologies.
- Target:- In simple words, a target holds the output of a task. A target could be a local(e.g: a file), HDFS or RDBMS(MySQL etc)
- Task:- Task is something where the actual work takes place. A task could be independent or dependent. The example of a dependant task is dumping the data into a file or database. Before loading the data the data must be there by any mean(scraping, API, etc). Each task is represented as a Python Class which contains certain mandatory member functions. A task function contains the following methods:
- requires():- This member function of the task class contains all the task instances that must be executed before the current task. In the example I shared above, a task, named ScrapeData, will be included in the
requires()method, hence make a task a dependant task. - output():- This method contains the target where the task output will be stored. This could contain one or more target objects.
- run():- This method contains the actual logic to run a task.
- requires():- This member function of the task class contains all the task instances that must be executed before the current task. In the example I shared above, a task, named ScrapeData, will be included in the
The pictorial representation will be something like below:

Let’s write a toy ETL first. It is doing nothing but put Hello World in a text file and then replace World with your input name.
import time
import luigi
# Task A - write hello world in text file
class HelloWorld(luigi.Task):
def requires(self):
return None
def output(self):
return luigi.LocalTarget('helloworld.txt')
def run(self):
time.sleep(15)
with self.output().open('w') as outfile:
outfile.write('Hello World!\n')
time.sleep(15)
# Task B - pick the text from helloworld.txt, replace World with the input name
class NameSubstituter(luigi.Task):
name = luigi.Parameter()
def requires(self):
return HelloWorld()
def output(self):
return luigi.LocalTarget(self.input().path + '.name_' + self.name)
def run(self):
time.sleep(15)
with self.input().open() as infile, self.output().open('w') as outfile:
text = infile.read()
text = text.replace('World', self.name)
outfile.write(text)
time.sleep(15)
if __name__ == '__main__':
luigi.run()
The very first Class or the Task,HelloWorld, is the extract part of the ETL, assume the text Hello World! is coming from an external source(API, DB, etc) and being stored in the file helloworld.txt. The output() method sets the target. Since the target is a local file LocalTarget with the file name helloworld.txt. The run method is taking care of all the processing logic thing. Since this task is not depending on any task hence requires() returns a None.
The second class NameSubstituter can be assumed a class transforming the original text into something else and saving into another text file. So, this class(task) is taking care of both T and L part of the ETL.
name = luigi.Parameter() is to parameterized the ETL which facilitates to accept data from the external data resources. The infile.read() reads the data from the incoming file, in our case, it is helloworld.txt and the content Hello World! is being saved in a text variable. The text World, then being replaced by the input name. Also the file name is following a certain format which is being set in the output() method.
Alright, the code is ready. It’s time to run it. I go to the command line and run the following command:
python luigitutorial.py --scheduler-host localhost NameSubstituter
Oops! it crashed!
LearningLuigi python luigitutorial.py --scheduler-host localhost NameSubstituter
Traceback (most recent call last):
File "luigitutorial.py", line 48, in <module>
luigi.run()
File "/Users/AdnanAhmad/Data/anaconda3/lib/python3.7/site-packages/luigi/interface.py", line 194, in run
luigi_run_result = _run(*args, **kwargs)
File "/Users/AdnanAhmad/Data/anaconda3/lib/python3.7/site-packages/luigi/interface.py", line 211, in _run
return _schedule_and_run([cp.get_task_obj()], worker_scheduler_factory)
File "/Users/AdnanAhmad/Data/anaconda3/lib/python3.7/site-packages/luigi/cmdline_parser.py", line 114, in get_task_obj
return self._get_task_cls()(**self._get_task_kwargs())
File "/Users/AdnanAhmad/Data/anaconda3/lib/python3.7/site-packages/luigi/task_register.py", line 88, in __call__
param_values = cls.get_param_values(params, args, kwargs)
File "/Users/AdnanAhmad/Data/anaconda3/lib/python3.7/site-packages/luigi/task.py", line 420, in get_param_values
raise parameter.MissingParameterException("%s: requires the '%s' parameter to be set" % (exc_desc, param_name))
luigi.parameter.MissingParameterException: NameSubstituter[args=(), kwargs={}]: requires the 'name' parameter to be set
As you can see, the error message is clear: requires the ‘name’ parameter to be set.
We’d have to pass the name parameter. For that we will do the following:
python luigitutorial.py --scheduler-host localhost NameSubstituter --name Adnan
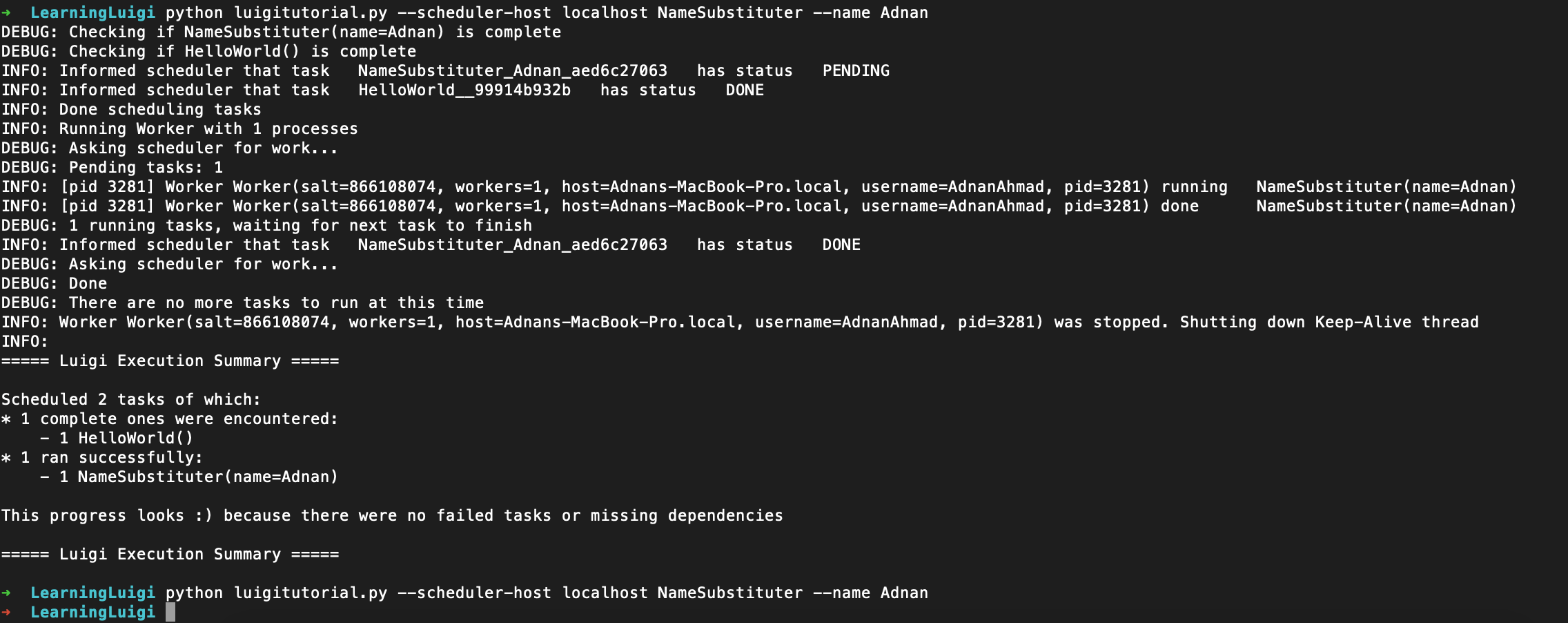
Can you see the smiley sign? It all goes well!
Now let me explain the command. Luigi uses a different kind of schedulers to schedule the jobs. For development purpose --local-schedular is used but if you want to visualize the process for the monitoring purpose than you should use --schedular-host to monitor it on a web-based interface. Make sure you run the luigid daemon which runs a local webserver. If you do not set --schedular-host it will still run but you can’t monitor the running task so DO take care of that! If all dots are connected well, you can see how the things going by visiting http://localhost:8082/
On a visit you can see screens like below:
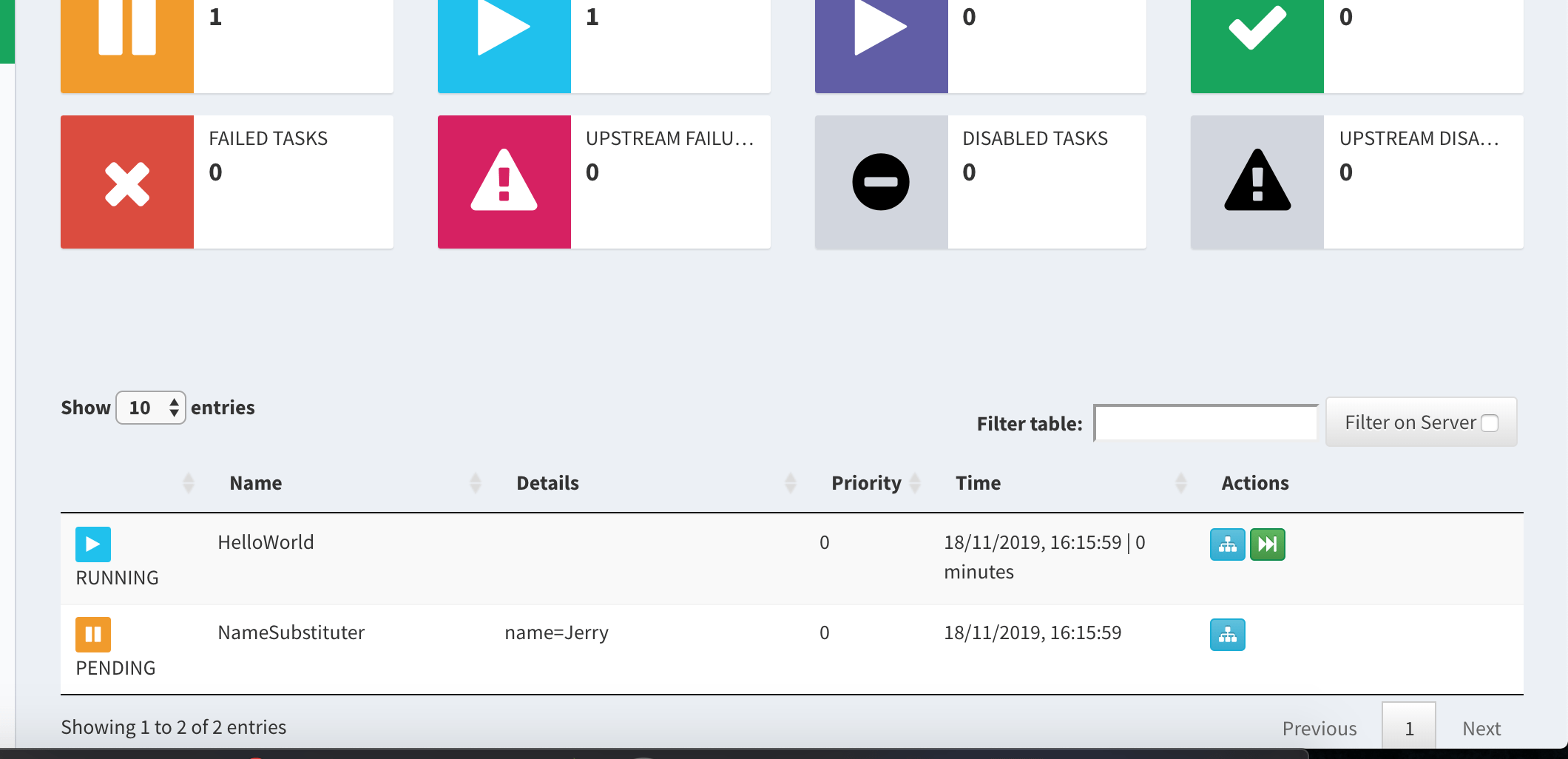
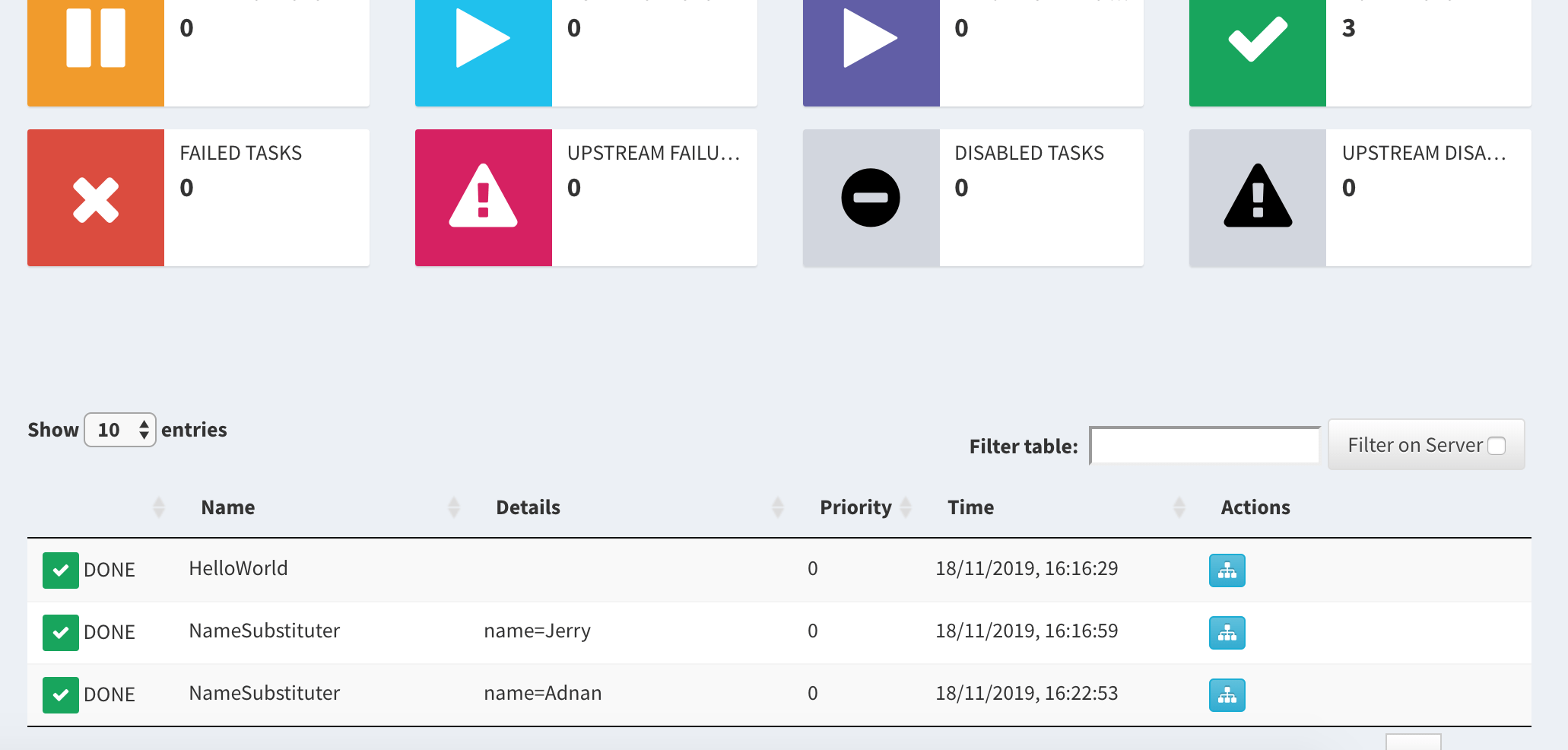
The tasks are running and you can see the status. In case you wonder why I added sleep, you can guess now. Without adding a delay you could not visualize it as it would execute very fast. Also notice multiple entries of NameSubstituter class with parameter in Details section. It is because they were considered unique jobs while HelloWorld was not.
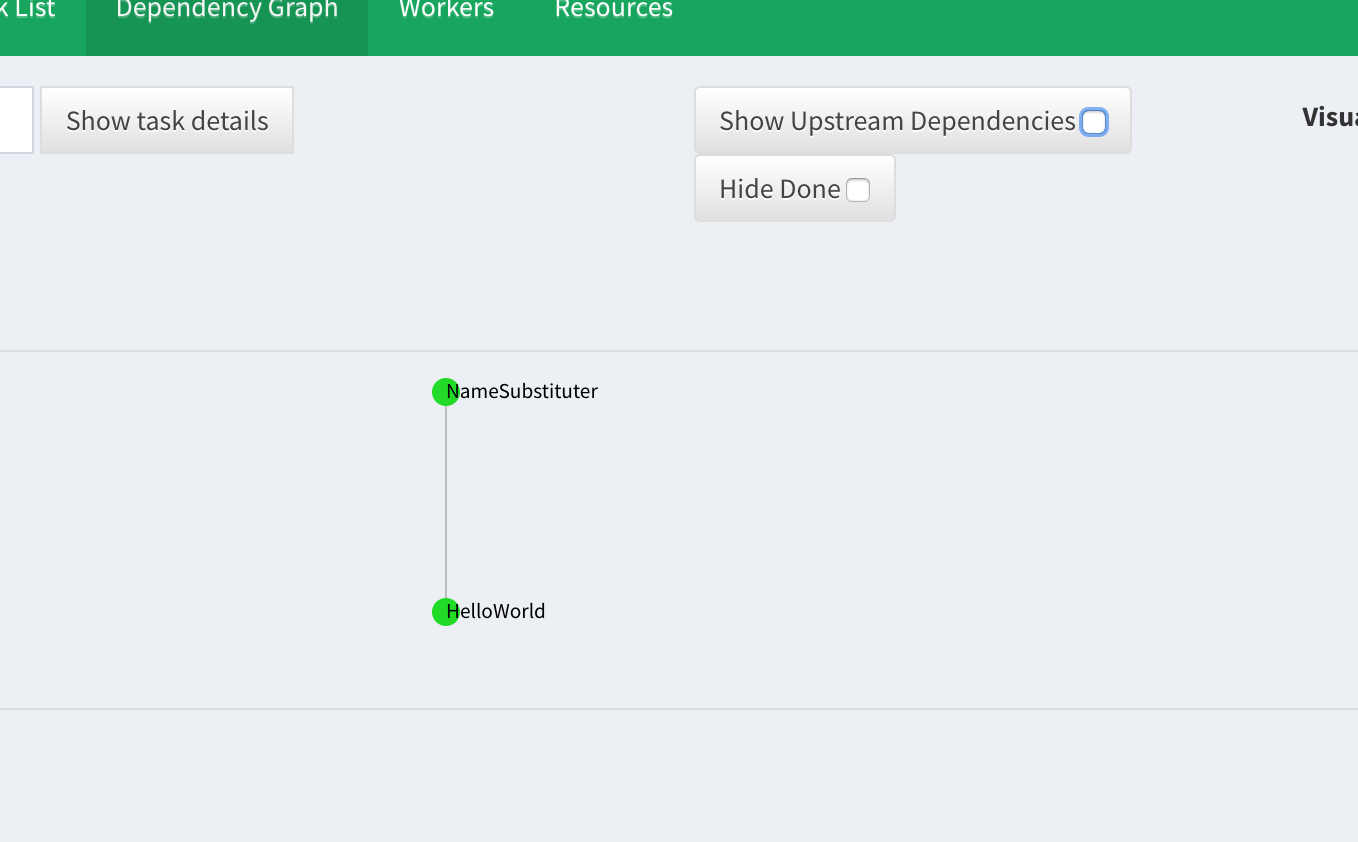
If you click an individual task you can see the dependency graph of tasks. Similar to Airflow.
-rw-r--r-- 1 AdnanAhmad staff 13 Nov 18 16:16 helloworld.txt -rw-r--r-- 1 AdnanAhmad staff 13 Nov 18 16:22 helloworld.txt.name_Adnan -rw-r--r-- 1 AdnanAhmad staff 13 Nov 18 16:16 helloworld.txt.name_Jerry
You see file names appended by the input name. If you remember we had set the file name like that. It is not necessary, you can pick whatever you want as I myself took it from an example.
Oh, by the way, the tasks are run once. It is not like files are generated on every run. If you want to take a fresh start than just delete all input and output files. In this example, if you, for instance, want to re-run the ETL with the name Adnan then just simply remove helloworld.txt.name_Adnan, not all files. If your input file content is changed then remove that as well.
Conclusion
So you learned how Luigi makes it easier to write ETLs for your needs. In the next part, we will be discussing a real-world example as we had done for Apache Airflow. Like always, the code is available on Github.


