
This post is the part of Scraping Series.
Usually, when you start developing a scraper to scrape loads of records, your first step is usually to go to the page where all listings are available. You go to the page by page, fetch individual URLs, store in DB or in a file and then start parsing. Nothing wrong with it. The only issue is the wastage of resources. Say there are 100 records in a certain category. Each page has 10 records. Ideally, you will write a scraper that will go page by page and fetch all links. Then you will switch to the next category and repeat the process. Imagine there are 10 categories on a website and each category had 100 records. So the calculation would be:
Total records = categories x records in a category = 10 x 100 = 1000
Total requests to fetch records in a category = No of Page x 10 = 10 Requests
Requests in 2 categories = 10 x 2 = 20
If a single request takes on average 500ms so for the above numbers it takes 10 seconds.
So with given numbers, you are always going to make 20 extra requests. If you have n categories so 10n extra requests.
The point I am trying to make is that you are wasting both time and bandwidth here for sure even if you avoid blocking by using proxies. So, what to do? Do we have an option? Yes, we can take advantage of sitemaps.
What is Sitemap
From Google
A sitemap is a file where you provide information about the pages, videos, and other files on your site, and the relationships between them. Search engines like Google read this file to more intelligently crawl your site. A sitemap tells Google which pages and files you think are important in your site, and also provides valuable information about these files: for example, for pages, when the page was last updated, how often the page is changed, and any alternate language versions of a page.
Basically, this single file holds all info that is required by Google to index your website. Though Google runs its own crawlers too and your site will be indexed even without a sitemap but this particular practice can help Google to fetch the info you want to be available as per your need. Usually, a sitemap URL looks like http://example.com/sitemap.xml but it is not necessary. The webmaster can change the default sitemap URL as per will. We will see further later in this post how to deal with such situations. A simple Sitemap file looks like the below(Credit: https://xmlsitemapgenerator.org/help/xml-sitemap-example.aspx):

The most important field for us is <loc> which actually holds a URL. When we will be parsing the XML file we will actually be using the info of this field. The other field that could help to set our parser frequency is changefreq. So if a URL is only changed on yearly basis then there is no need to hit it daily. You might be wondering about the situation; say, you are building a price monitoring system where you are supposed to check when the price changes. For instance, on an e-commerce site that sells clothes and shoes, there is a probability that shoe prices change on a weekly basis but clothes price change on monthly basis. You could store this info and tune in your crawler accordingly.
Alright so let’s do some work. Earlier I had scraped the Airbnb website. Now we will deal with it differently. Our first goal to find the sitemap URL. Unfortunately, this is not the default sitemap.xml URL. So how do we find it, brute force? No. All I am going to check the robots.txt file. This file is actually for search engine and it contains all instructions on what to crawl or what not to crawl. Like a sitemap file, this file is also at the root of the domain. Fortunately, this file will always be a robots.txt file hence you can always refer to it for the sitemap. If you visit Airbnb robots.txt file (https://www.airbnb.com/robots.txt), you will find the sitemap entry in it.
Sitemap: https://www.airbnb.com/sitemap-master-index.xml.gz
This is a kind of syntax. You mention Sitemap: and after that the root URL of your sitemap file. If you notice it is a compressed file hence will have to download and uncompress it. You may download it manually or automate it, it is not the topic of this post. Once I uncompress it I find the file sitemap-master-index.xml in it. If you open it you will find entries like the below:

As you can see it contains more .gz files. What all we have to do is to explore one by one or figure out and download that file only and unzip it.
If you open and view the file sitemap-master-index.xml file you will find .gz files like https://www.airbnb.com/sitemap-homes-urls-11.xml.gz, https://www.airbnb.com/sitemap-homes-urls-12.xml.gz, etc and there are many such links. Let’s download sitemap-homes-urls-11.xml.gz and see what is inside. It’s a pretty huge file in MBs. Let’s write the code to fetch all URLs in the file.
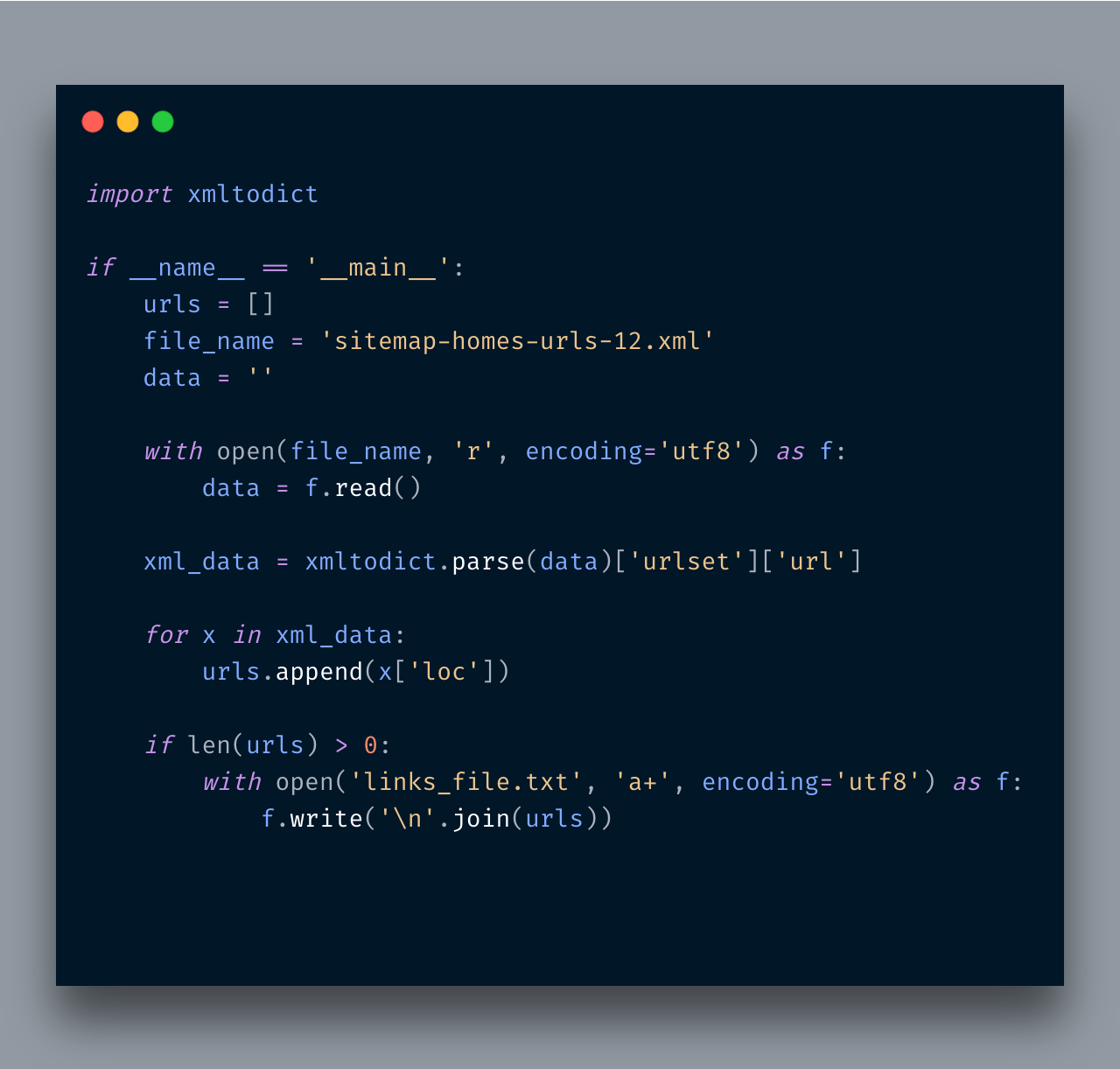
This snippet reads the sitemap file, use xmltodict to convert it into a dict and then iterate URLs and save them into a file. Once this is done, you will find there were 50K records. You will find individual URLs like https://www.airbnb.com/rooms/39348588 there. Now imagine fetching all 50K URLs by going page by page. Even if there are 100 records per page you will still need to go make 50 requests. Yeah, 50 additional requests! Here is one request, you have all of them. Cool, No?
Alright, now I am going to pick one of the links and will scrape some info. I am going to use Scraper API. Why because when I tried to scrape it normally I did not get the info as the page was being generated dynamically via Javascript. So the best option is to use an online cloud-based API to scrape the info which also provides remote headless scraping.
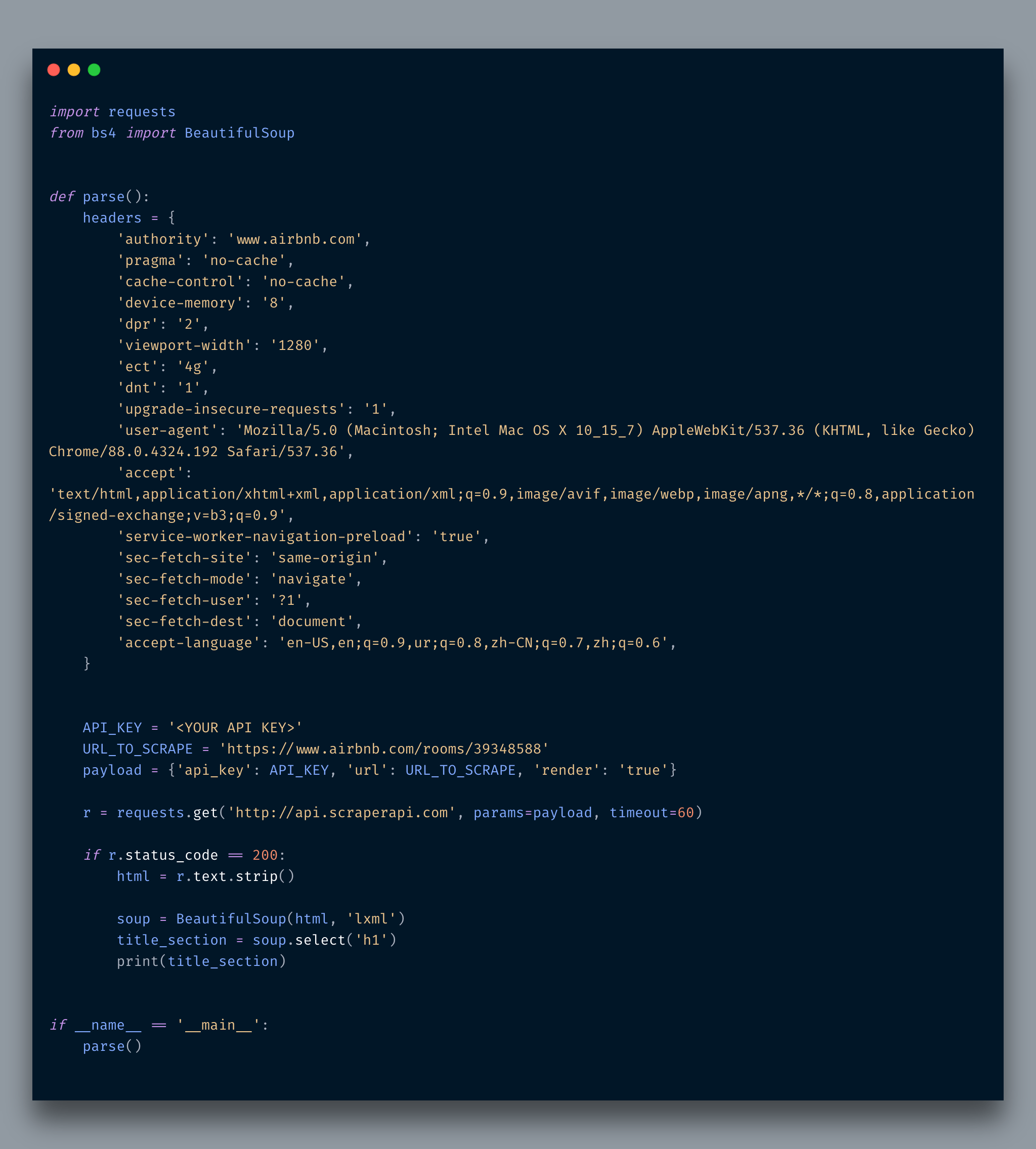
For sake of example, I only have scraped the title as the purpose of this post was to educate you about the approach of getting individual URLs.
Conclusion
In this post, you learned a trick of getting parsing links which makes your entire flow more manageable and easy. You can automate the entire process: From access the main Sitemap URL and download and extracting zip files and then saving records into a file.
Oh if you sign up here with my referral link or enter promo code adnan10, you will get a 10% discount on it. In case you do not get the discount then just let me know via email on my site and I’d sure help you out.
Related posts:
 Develop AirBnb Parser in Python
Develop AirBnb Parser in Python
 ScrapingBee API Python Tutorial: How to Use Render JS, Proxies & Headers
ScrapingBee API Python Tutorial: How to Use Render JS, Proxies & Headers Learn how to use cloud based Scraping API to scrape web pages without getting blocked.
 Create Amazon Scraper in Python using Scraper API
Create Amazon Scraper in Python using Scraper API Learn how to create an Amazon scraper in python to scrape product details like price, ASIN etc
