This post is part of the GenAI series.
Alright, so the first text-based GenAI app that I am going to build is actually an AI-based recipe generator in PHP Laravel using OpenAI APIs. The app will ask about the ingredients and cuisine type and will generate a recipe for you. If you are in a hurry, you can watch the demo of the app below:
To build this app, you will need to install Laravel and generate OpenAI API keys.
Development Setup
To make this app work you need three things:
- OpenAI API key generation
- Laravel installation
- OpenAI Integration
OpenAI API Key generation
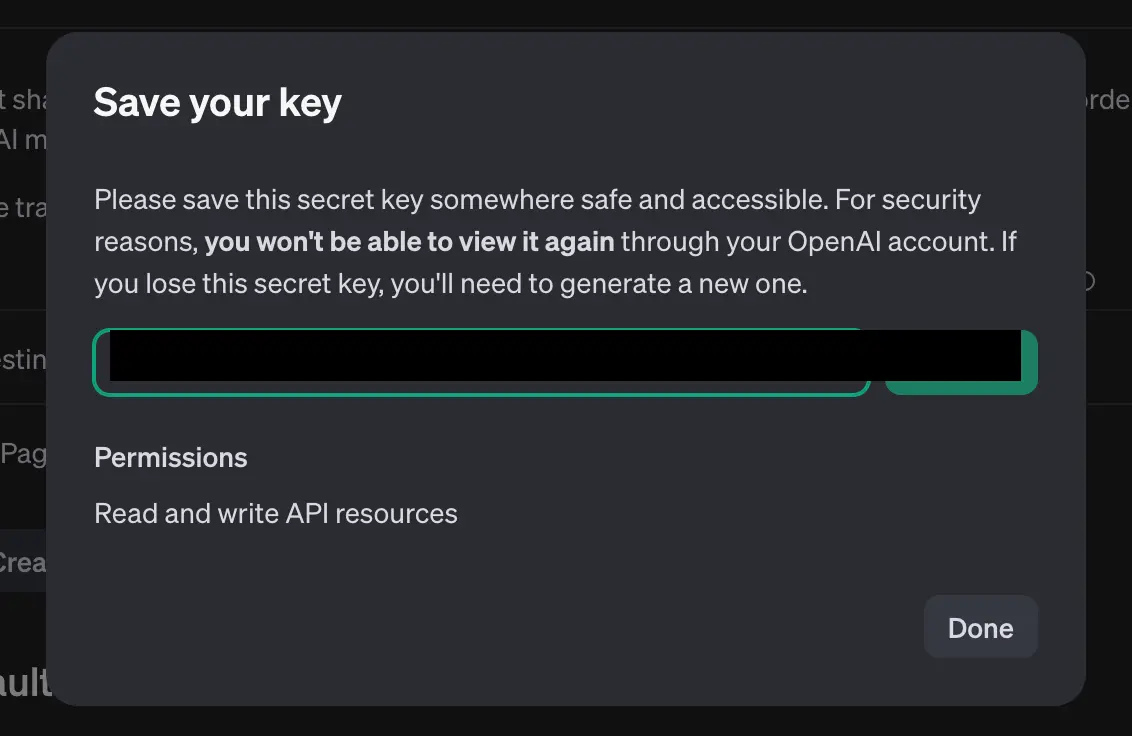
Go to the API Keys section of the OpenAI Platform generate a new key that starts with sk- and save it somewhere. (Image below edited via chatGPT)
Laravel Installation
Assuming you have composer installed, you can run the following command:
composer create-project laravel/laravel recipegenerator
It will create a folder with the name recipegenerator.
Now, run npm install to install Node packages. If all goes well, you will see something like the output below:
Let’s generate HomeController:
php artisan make:controller HomeController
and then a view:
php artisan make:view home
The HomeController.php file will look like this:
namespace App\Http\Controllers;
use Illuminate\Http\Request;
class HomeController extends Controller
{
public function index()
{
return view('home');
}
}
and home.blade.php file:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>AI Recipe Generator</title>
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/bootstrap@4.6.2/dist/css/bootstrap.min.css">
</head>
<body>
<div class="container">
<div style="margin-top: 30px;" class="row text-center">
<div class="col-md-12">
<img width="100" height="100" src="{{url('logo.webp')}}" alt="">
<h1>Recipie Generator</h1>
</div>
</div>
<div class="row">
<div class="col-md-12">
<form action="">
<div class="form-group">
<label for="ing">Ingredients:</label>
<input type="text" class="form-control" id="ing" placeholder="Potato, Tomato etc..">
<label for="cuisine">Cuisine</label>
<select class="form-control" name="cuisines" id="cuisineDropdown">
<option value="italian">Italian</option>
<option value="chinese">Chinese</option>
<option value="mexican">Mexican</option>
<option value="indian">Indian</option>
<option value="japanese">Japanese</option>
<option value="french">French</option>
<option value="thai">Thai</option>
<option value="greek">Greek</option>
<option value="spanish">Spanish</option>
<option value="middleEastern">Middle Eastern</option>
</select>
</div>
<button type="submit" class="btn btn-danger">Generate</button>
</form>
</div>
</div>
</div>
</body>
</html>
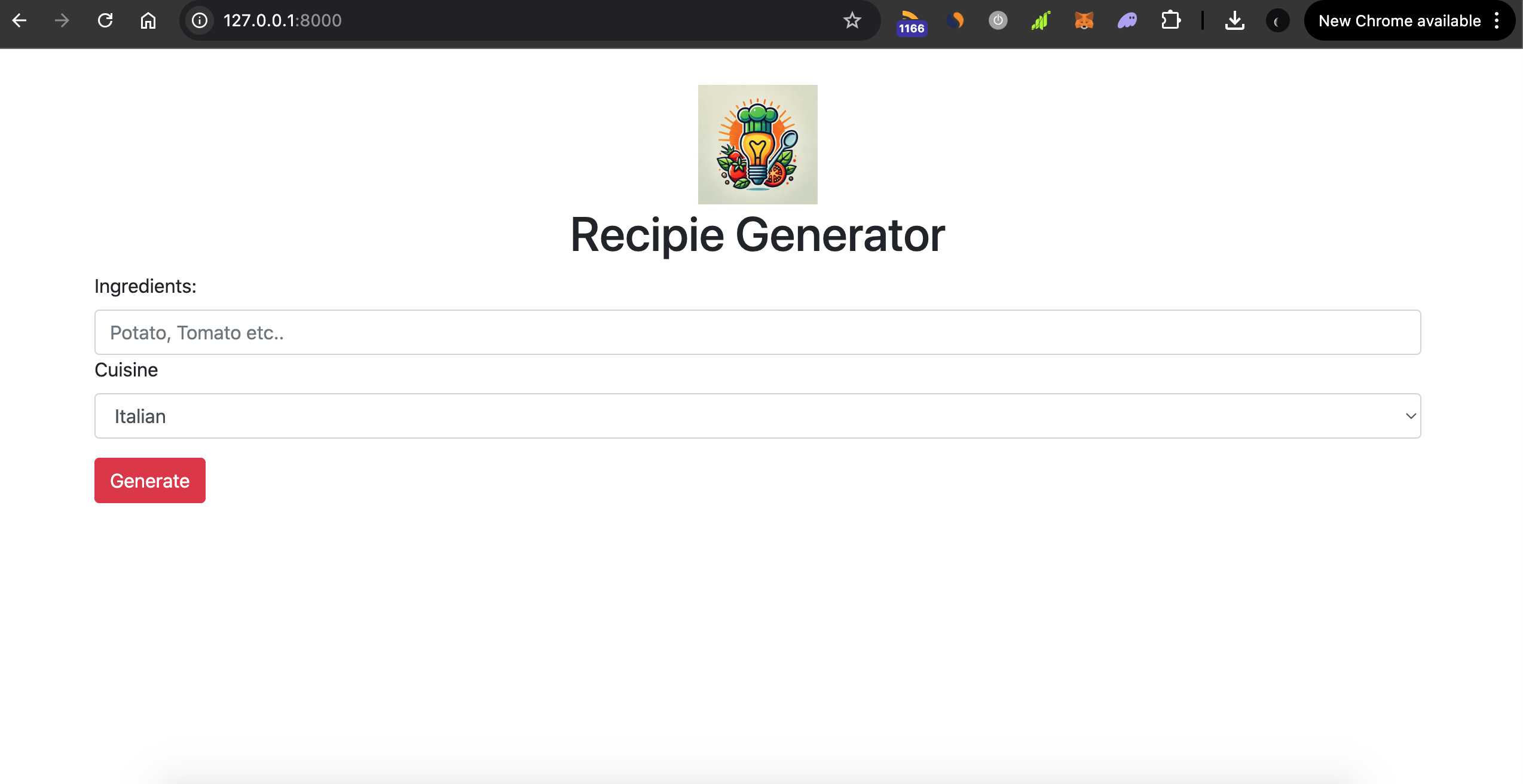
And you will see something like the following:
OpenAI Integration
To integrate OpenAI with your PHP application you will need to install this unofficial but awesome library.
composer require openai-php/client
I am going to add another route, generate, that will interact with OpenAI GPT APIs and generate a recipe.
OpenAI provides an array of APIs to interact with their different services: Chat, Audio, Embeddings, Fine-tuning, Assistant, and many others. We are going to use Chat Completion API for our app. This could be called the default feature of the chatGPT which is when you ask something on GPT, it uses the chat completion APIs internally.
Below is the code that is interacting with GPT:
public function generate(Request $request)
{
$apiKey = getenv('OPENAI_KEY');
$client = \OpenAI::client($apiKey);
$result = $client->chat()->create([
'model' => 'gpt-4o-mini',
'temperature'=>0.5,
'max_tokens' => 150,
'messages' => [
['role' => 'system', 'content' => 'You are helpful assistant'],
['role' => 'user', 'content' => 'Hello!'],
],
]);
dd($result);
}
I opted for the latest gpt-4o-mini model because it is cheaper, faster, and sufficient for what we are looking for. You can see the list of models here.
The temperature parameter controls the randomness that causes hallucinations. The value ranges between 0 and 1. The lesser the value, the more deterministic it is.
max_tokens tells about the maximum number of tokens that can be generated in the chat completion. OpenAI provides an online tokenizer tool that is quite helpful.
messages field contains both prompts and instructions to generate a response. When you send a message to GPT, your role is a user. When GPT responds, its role is an assistant. You can set the tone of the response by using another role called system. In chatGPT, you set the tone by adding Custom Instructions as I have done here.
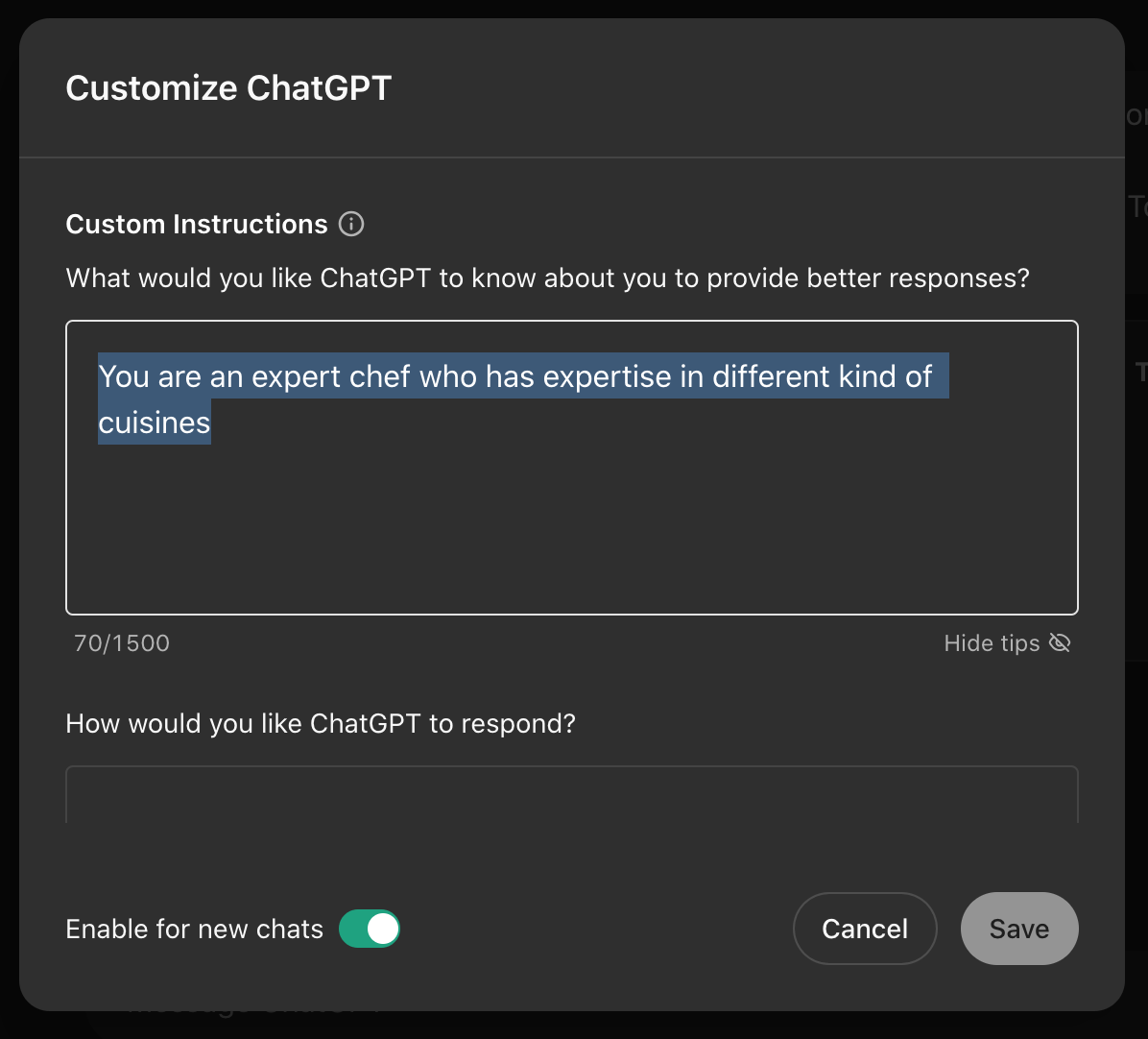
When I run the above code it returns the following:
OpenAI\Responses\Chat\CreateResponse {#282 ▼ // app/Http/Controllers/HomeController.php:28
+id: "chatcmpl-A6Cunhx6HVafxPgPPiZmO6zWkDKsB"
+object: "chat.completion"
+created: 1726042977
+model: "gpt-4o-mini-2024-07-18"
+systemFingerprint: "fp_54e2f484be"
+choices: array:1 [▼
0 =>
OpenAI\Responses\Chat
\
CreateResponseChoice {#278 ▼
+index: 0
+message:
OpenAI\Responses\Chat
\
CreateResponseMessage {#271 ▼
+role: "assistant"
+content: "Hello! How can I assist you today?"
+toolCalls: []
+functionCall: null
}
+finishReason: "stop"
}
]
+usage:
OpenAI\Responses\Chat
\
CreateResponseUsage {#270 ▼
+promptTokens: 17
+completionTokens: 9
+totalTokens: 26
}
-meta:
OpenAI\Responses\Meta
\
MetaInformation {#276 ▼
+requestId: "req_445c1ee052f9ef65451b450ce29e7788"
+openai:
OpenAI\Responses\Meta
\
MetaInformationOpenAI {#267 ▶}
+requestLimit:
OpenAI\Responses\Meta
\
MetaInformationRateLimit {#279 ▼
+limit: 10000
+remaining: 9999
+reset: "6ms"
}
+tokenLimit:
OpenAI\Responses\Meta
\
MetaInformationRateLimit {#268 ▼
+limit: 10000000
+remaining: 9999840
+reset: "0s"
}
}
}
Check the usage section:
+usage:
OpenAI\Responses\Chat
\
CreateResponseUsage {#270 ▼
+promptTokens: 17
+completionTokens: 9
+totalTokens: 26
}
It tells you about both input and output tokens. promptTokens tell the number of tokens used in the prompt and in the output. The completionTokens tells about the token count generated by OpenAI API. If you go to the tokenizer website it shows something like the below:
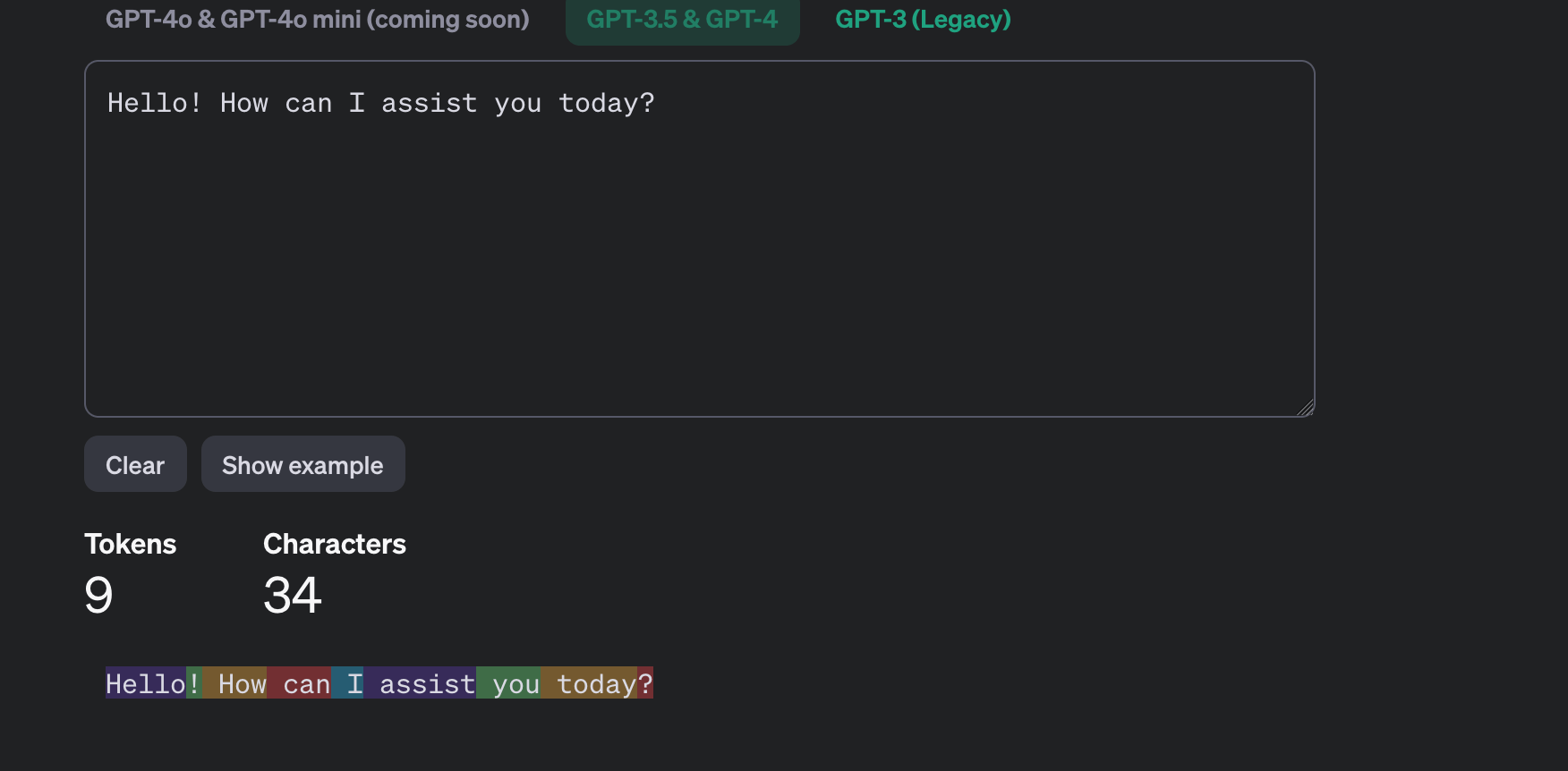
Now I am modifying the code to incorporate the actual prompt and other settings:
public function generate(Request $request)
{
$apiKey = getenv('OPENAI_KEY');
$ingredients = $request->get("ingredients");
$cuisine = $request->get("cuisine");
$prompt = "Generate a recipe based on the following information:\n
Ingredients: {$ingredients}\n
Cuisine: {$cuisine}
";
$client = \OpenAI::client($apiKey);
$result = $client->chat()->create([
'model' => 'gpt-4o-mini',
'temperature'=>0.3,
'max_tokens' => 500,
'messages' => [
['role' => 'system', 'content' => 'You are an expert chef who has expertise in different kind of cuisines.'],
['role' => 'user', 'content' => $prompt],
],
]);
// dd($result->choices[0]->message->content);
dd($result);
}
It worked, but there’s an issue; it consumed more than 500 tokens to return a complete response. I tweaked the system prompt and made it like this:
You are an expert chef who has expertise in different kind of cuisines. The generated Recipe should have only the following headings: Ingredients and Instructions
$result = $client->chat()->create([
'model' => 'gpt-4o-mini',
'temperature'=>0.3,
'max_tokens' => 500,
'messages' => [
['role' => 'system', 'content' => 'You are an expert chef who has expertise in different kind of cuisines. The generated Recipe should have only the following headings: Ingredients and Instructions'],
['role' => 'user', 'content' => $prompt],
],
]);
And now it consumed 421 tokens only. You can track the usage by visiting here.
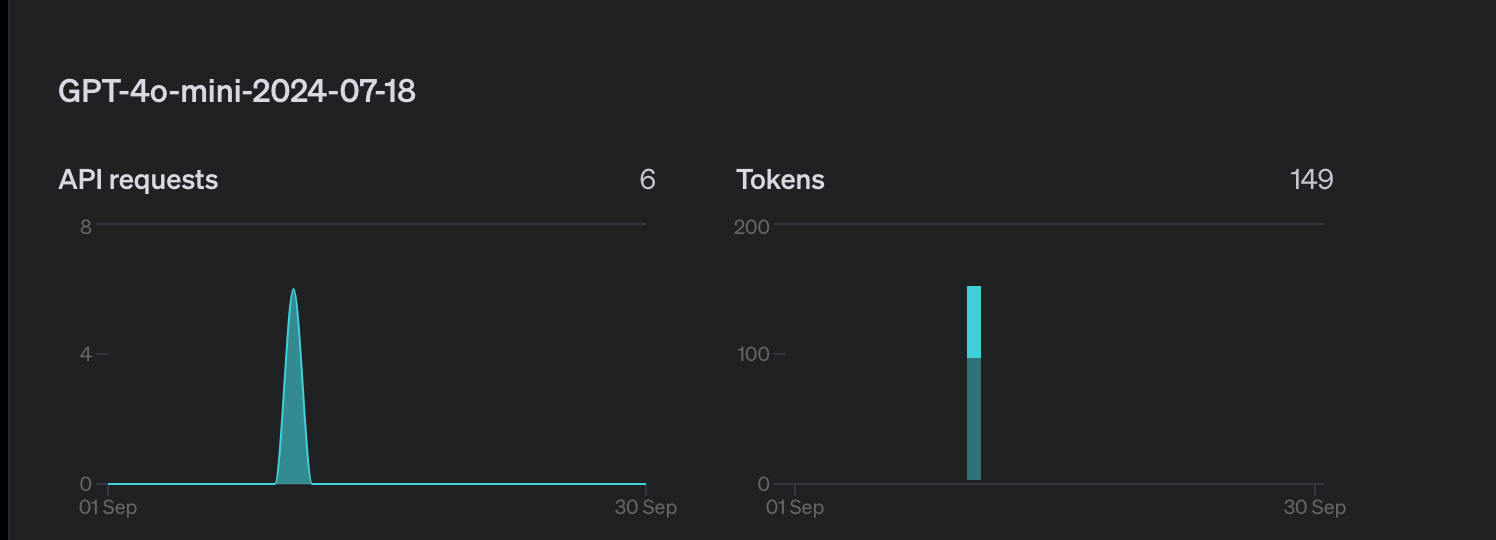
Since I want to use AJAX to make a call, I am returning the data in JSON format
return response()->json([
'status' => 'OK',
'message' => $result->choices[0]->message->content,
]);
In Postman it generates an output like the below:
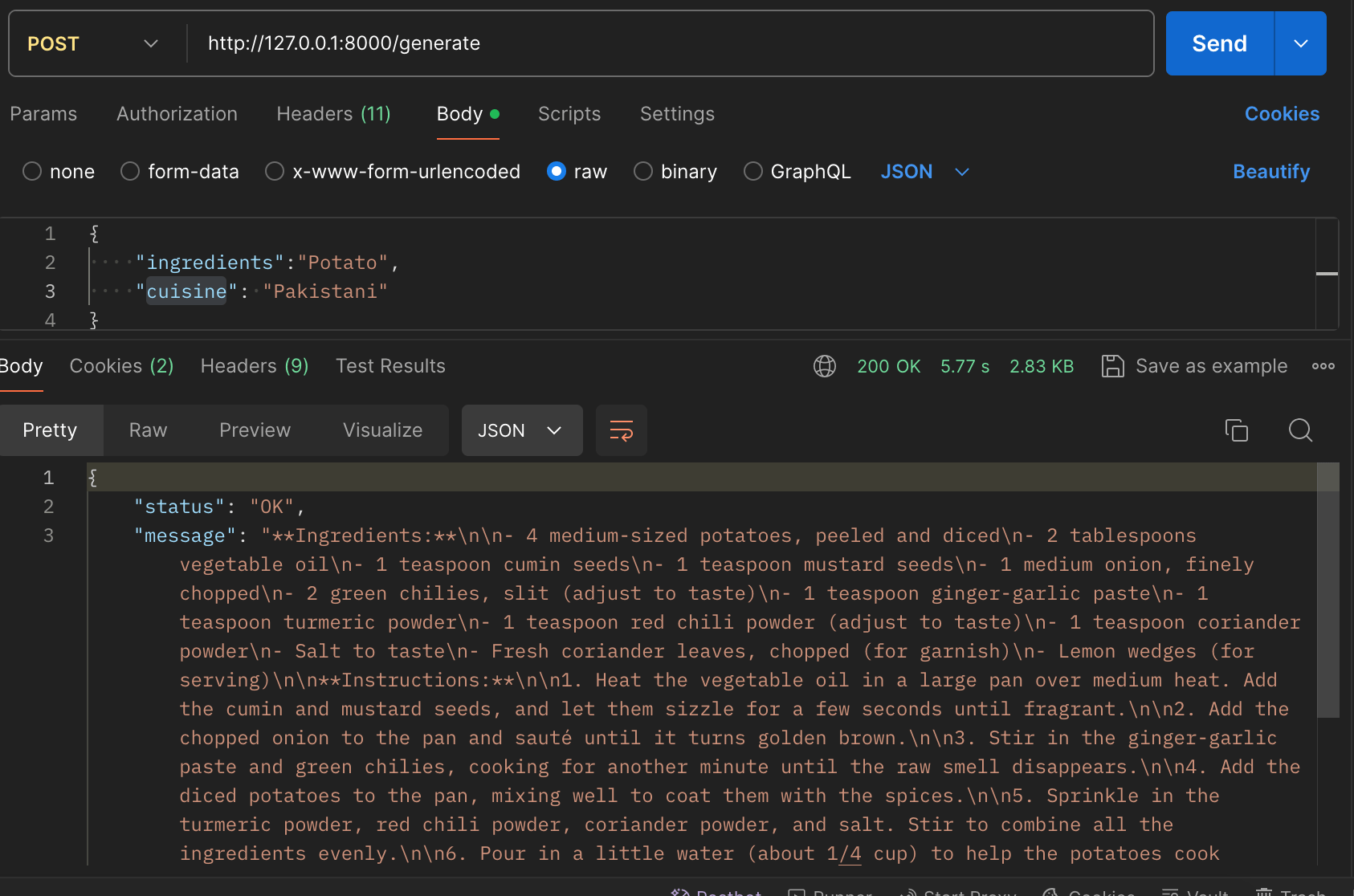
All is well. Now, what is needed to retrieve this data via AJAX and display it on the page? Here’s the relevant code snippet:
if (ingredients!= null && cuisine != null) {
$.ajax({
url: '{{ route("generate") }}',
type: 'POST',
data: {
_token: $('meta[name="csrf-token"]').attr('content'), // CSRF token
ingredients: ingredients,
cuisine: cuisine
},
success: function (response) {
const converter = new showdown.Converter()
var markdownText = response.message
const html = converter.makeHtml(markdownText);
$('#recipe').html(html)
$('#wait').addClass('d-none')
},
error: function (xhr, status, error) {
// Handle errors
console.log(xhr.responseText);
$('#wait').addClass('d-none')
$('#recipeResult').html('<p>Error: ' + xhr.responseText + '</p>');
}
});
}
It generated the response in Markdown so I used a library to convert it into HTML format.

Hmm, it looks good, but there’s an issue; there’s no indication of what the recipe name is. I converted the system prompt to the following:
You are an expert chef who has expertise in different kind of cuisines. The generated Recipe should have only the following headings: Recipe name, Ingredients and Instructions

Conclusion
So as you saw, by adding a few lines you can make your app an AI app, an AI wrapper app, that leverages LLM APIs to produce useful apps. Like always, the code is available on Github. Like always, the code is available on Github.